À medida que as aplicações crescem, os bancos de dados enfrentam um gargalo inevitável. Tabelas com bilhões de linhas tornam as consultas lentas, os backups demorados e os índices pesados demais para a memória. Quando você atinge o limite do que um único servidor pode suportar (escalabilidade vertical), a solução é “dividir para conquistar”.
É aqui que entram duas das arquiteturas mais importantes da Engenharia de Dados e de Software: Partitioning (Particionamento) e Sharding (Fragmentação). Embora frequentemente confundidos, eles resolvem problemas de escala de maneiras fundamentalmente diferentes.
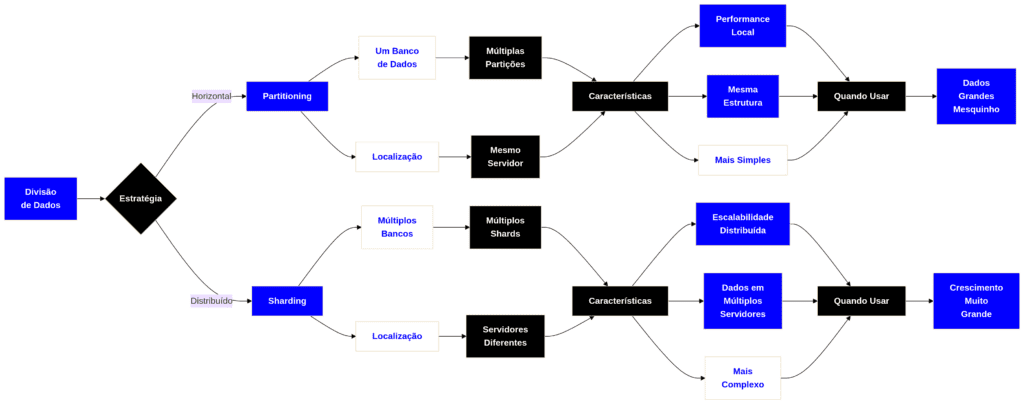
O que é Partitioning (Particionamento)?
O particionamento é a técnica de dividir uma tabela lógica muito grande em pedaços físicos menores e mais gerenciáveis, dentro do mesmo banco de dados ou servidor. O sistema de banco de dados gerencia essas partições de forma transparente; para a aplicação, parece que ela ainda está consultando uma única tabela gigante.
Existem dois tipos principais de particionamento:
| Particionamento Vertical | Particionamento Horizontal |
| Divide a tabela por colunas. Exemplo: Uma tabela de “Usuários” pode ter colunas de acesso frequente (ID, Nome, Email) em uma partição, e colunas pesadas e de acesso raro (Foto de Perfil, Biografia longa) em outra. Isso economiza memória e acelera leituras (I/O). | Divide a tabela por linhas. Exemplo: Uma tabela de “Vendas” pode ser particionada por data. Vendas de 2024 ficam em uma partição, 2025 em outra. Benefício: Se você consultar apenas as vendas de hoje, o banco de dados ignora as partições antigas (técnica chamada Partition Pruning), acelerando drasticamente a consulta. |
O que é Sharding (Fragmentação)?
O Sharding é, na verdade, uma forma extrema de particionamento horizontal. A diferença crucial é a infraestrutura: no Sharding, os dados são divididos e distribuídos em múltiplos servidores físicos ou instâncias de banco de dados independentes (chamados de Shards).
Nesta arquitetura, conhecida como Shared-Nothing (Nada Compartilhado), cada Shard atua como um banco de dados autônomo contendo apenas uma fatia dos dados totais.
- Como funciona: Uma “Chave de Shard” (Shard Key) determina para qual servidor o dado vai. Se você fizer o sharding por “Região”, o Shard A pode guardar os clientes do Brasil, o Shard B os dos EUA, e o Shard C os da Europa.
- Por que usar: Quando um único servidor (mesmo o mais caro e potente do mercado) não tem mais CPU, RAM ou disco suficiente para lidar com o volume de dados ou de requisições simultâneas. O Sharding permite escalabilidade horizontal infinita: basta adicionar mais servidores baratos ao cluster.
Principais Diferenças
A tabela abaixo destaca o contraste direto entre as duas abordagens:
| Característica | Partitioning | Sharding |
| Localização dos Dados | Mesmo servidor / mesma instância de banco de dados. | Múltiplos servidores independentes (Nós/Nodes). |
| Objetivo Principal | Facilidade de manutenção (ex: apagar dados velhos) e otimização de consultas locais. | Escalabilidade massiva de processamento (CPU/RAM) e armazenamento além do limite de uma máquina. |
| Complexidade da Aplicação | Baixa. O banco de dados gerencia tudo. A aplicação nem percebe a divisão. | Alta. A aplicação (ou um roteador intermediário) precisa saber para qual servidor enviar a query. |
| Disponibilidade | Se o servidor cair, todos os dados ficam indisponíveis. | Se um Shard cair, apenas a fatia de dados dele fica offline; o resto do sistema continua operando. |
| Consultas Complexas (JOINs) | Simples. Joins funcionam normalmente pois os dados estão na mesma máquina. | Muito difícil. Fazer JOIN entre dados que estão em servidores físicos diferentes causa grande lentidão na rede. |
Particionamento na Prática: O E-commerce e o Relatório Lento
Imagine que você trabalha na engenharia de dados de um grande e-commerce. Vocês têm uma tabela chamada Pedidos no PostgreSQL que armazena todas as vendas desde a fundação da empresa, há 10 anos. Essa tabela tem 5 bilhões de linhas.
O Problema:
Toda vez que o time de marketing tenta puxar um relatório das “vendas de ontem”, a query demora minutos para rodar. Além disso, o índice dessa tabela ficou tão gigante que não cabe mais na memória RAM do servidor (que custa caro).
A Solução (Particionamento Horizontal por Data):
Você decide particionar a tabela Pedidos por mês e ano.
- Como fica nos bastidores: O banco de dados cria tabelas físicas menores “escondidas” (ex:
pedidos_2025_12,pedidos_2026_01,pedidos_2026_02). - A Mágica (Partition Pruning): Quando o marketing roda um
SELECT * FROM Pedidos WHERE data = '04/03/2026', o banco de dados é inteligente o suficiente para saber que não precisa ler a tabela inteira. Ele vai direto na partiçãopedidos_2026_03e ignora todo o resto. O relatório que demorava minutos passa a rodar em milissegundos. - Manutenção: Se a política da empresa diz que dados com mais de 5 anos devem ser apagados, você não roda um comando
DELETE(que travaria o banco e consumiria muito processamento). Você simplesmente roda umDROP PARTITION pedidos_2021_01. A exclusão de milhões de linhas acontece instantaneamente, liberando espaço no disco.
Agora imagine que você é o arquiteto de um sistema de CRM (SaaS) global, parecido com o Salesforce. Vocês têm milhares de empresas como clientes.
O Problema:
O sistema faz 100.000 gravações (inserções e atualizações) por segundo. O servidor de banco de dados atual chegou a 100% de uso de CPU, a memória RAM está no limite e o disco não consegue gravar dados mais rápido do que isso. Fazer um particionamento não vai ajudar, porque a máquina física não aguenta mais o tráfego.
A Solução (Sharding Baseado em ID do Cliente):
Você decide transformar seu banco de dados único em um cluster de múltiplos servidores independentes (Shards). Você escolhe o id_empresa como a sua Chave de Shard (Shard Key).
- Como fica nos bastidores:
- Servidor 1 (Shard A): Armazena todos os dados das Empresas de ID 1 a 10.000.
- Servidor 2 (Shard B): Armazena todos os dados das Empresas de ID 10.001 a 20.000.
- Servidor 3 (Shard C): Armazena todos os dados das Empresas de ID 20.001 a 30.000.
- A Mágica (Roteamento): Quando um funcionário da Empresa 15.000 faz login e tenta salvar um novo cliente no CRM, a sua aplicação (ou um roteador de banco de dados intermediário) avalia a requisição. Ele vê o ID 15.000 e pensa: “A Empresa 15.000 mora no Servidor 2”. A requisição de gravação é enviada exclusivamente para o Servidor 2.
- Escalabilidade Infinita: O Servidor 1 e o Servidor 3 nem ficam sabendo dessa transação. Você acabou de dividir o uso de CPU, RAM e Disco por três. Se o SaaS continuar crescendo e vocês ganharem mais 10.000 empresas clientes, basta comprar um Servidor 4 (Shard D) e plugar na arquitetura.
Resumo do Impacto Prático
| Cenário Prático | O que você quer resolver? | Estratégia Recomendada | Exemplo de Ação |
| Tabela “Obesa” | Consultas lentas em relatórios e dificuldade de apagar dados velhos. A máquina ainda aguenta o tráfego. | Partitioning | Dividir a tabela de histórico de transações por Mês/Ano. |
| Hardware no Limite | Muitos usuários simultâneos gravando e lendo dados; CPU e RAM do maior servidor do mercado já não dão conta. | Sharding | Dividir o banco de dados por Região (América Latina no Servidor 1, Europa no Servidor 2). |
A implementação do particionamento geralmente é nativa e mais simples (bancos como PostgreSQL e MySQL fazem isso muito bem). Já o sharding adiciona uma camada de complexidade grande na engenharia, pois a sua aplicação precisa saber como rotear as informações.
Quando escolher qual?
A regra de ouro na arquitetura de dados é: Evite o Sharding até que ele seja absolutamente necessário.
Vá de Partitioning quando:
- Você tem tabelas gigantes (ex: logs, histórico financeiro) que estão deixando os relatórios lentos.
- Você precisa arquivar ou deletar dados antigos rapidamente (basta “dropar” a partição do mês passado, o que é instantâneo em comparação a deletar milhões de linhas).
- Seu hardware atual ainda tem capacidade de CPU e memória, o problema é apenas a organização do dado no disco.
Vá de Sharding quando:
- Você atingiu o limite de hardware. Fazer um upgrade no servidor atual custaria uma fortuna ou é fisicamente impossível.
- Sua aplicação tem uma carga massiva de gravação (Writes) que um único disco não consegue processar.
- Você precisa de distribuição geográfica (ex: guardar dados de europeus na Europa por questões de latência ou conformidade com a GDPR).
O Desafio do Sharding: O “Hotspot”
Um dos maiores riscos do Sharding é escolher a chave errada, criando um Hotspot (ponto quente). Por exemplo, se você dividir um banco de dados de uma rede social pela letra inicial do nome, o servidor responsável pela letra “A” e “M” receberá 80% do tráfego e vai travar, enquanto o servidor das letras “X”, “Y” e “Z” ficará ocioso. A distribuição precisa ser perfeitamente balanceada.
