Na engenharia e arquitetura de dados, a forma como você organiza as tabelas de um banco de dados dita o desempenho, a integridade e a escalabilidade do sistema. O grande dilema na hora de criar esse modelo físico geralmente se resume a dois caminhos: Normalização e Desnormalização.
Eles não são inimigos, mas sim estratégias opostas usadas para resolver problemas diferentes. A normalização foca na escrita e integridade (OLTP), enquanto a desnormalização foca na velocidade de leitura (OLAP).
O que é Normalização?
A normalização é o processo de organizar os dados em um banco de dados relacional para reduzir a redundância e melhorar a integridade. O objetivo é garantir que cada pedaço de informação seja armazenado em apenas um lugar. Quando você precisa atualizar o nome de um cliente, por exemplo, você altera apenas uma linha em uma única tabela, e não em centenas de registros de vendas.
Para atingir esse nível de organização, aplicamos regras progressivas chamadas de Formas Normais (FN).
O processo de normalização aplica uma série de regras sobre as tabelas de um banco de dados para verificar se estas estão corretamente projetadas.
Embora existam cinco formas normais (ou regras de normalização), na prática usamos um conjunto de três Formas Normais, ou seja, um banco de dados é considerado normalizado se nele foram aplicadas as regras destas três formas normais.
O que é Desnormalização?
A desnormalização é o processo intencional de adicionar redundância a um banco de dados que já foi normalizado. O objetivo é melhorar a performance de leitura.
Em sistemas de Data Warehouse ou Analytics (OLAP), fazer dezenas de JOINs para montar um relatório através de tabelas na 3FN é extremamente lento. A desnormalização “achata” essas tabelas, agrupando dados frequentemente consultados em um lugar só.
- Exemplo Prático: Em vez de fazer um JOIN entre
Vendas,Clientes,CidadeseEstadospara saber o total vendido em São Paulo, você cria uma tabela desnormalizada gigante (Fato/Dimensão) onde a linha da venda já contém o nome da cidade e do estado, mesmo que isso repita a palavra “São Paulo” um milhão de vezes.
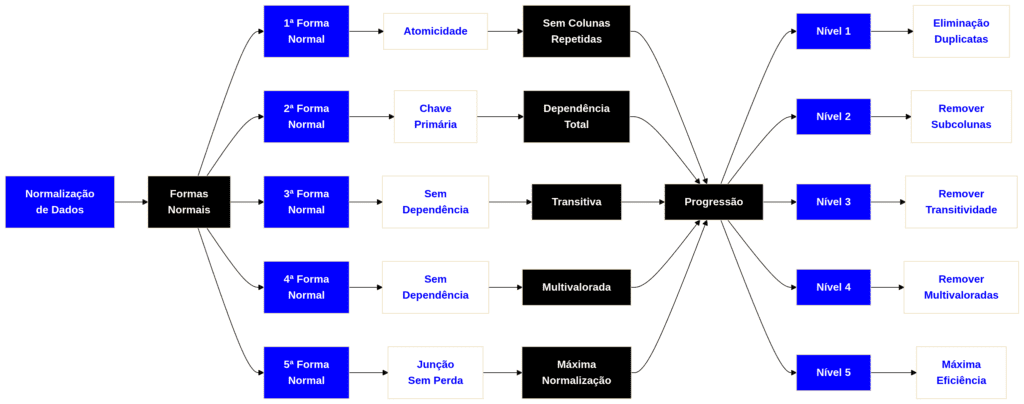
1ª Forma Normal (1FN): Atomicidade
A regra de ouro aqui é: cada coluna deve conter apenas um valor único e indivisível (atômico), e não pode haver grupos repetidos. Uma entidade estará na primeira forma normal (IFN) se todos os campos forem atômicos (simples) e não multivalorados (com múltiplos valores).
Problema (Não Normalizado): Uma tabela de livros onde um livro possui vários autores na mesma célula.
| ID_Livro | Titulo | Autores |
| 101 | Engenharia de Dados | João Silva, Maria Souza |
| 102 | Redes Neurais | Carlos Dias |
Solução (1FN): Dividir em múltiplas linhas, garantindo que a coluna Autores tenha apenas um valor por registro.
| ID_Livro | Titulo | Autor |
| 101 | Engenharia de Dados | João Silva |
| 101 | Engenharia de Dados | Maria Souza |
| 102 | Redes Neurais | Carlos Dias |
Quais os problemas de uma tabela não normalizada com a 1FN?
São vários. A primeira forma normal tenta resolver um dos maiores problemas de bancos de dados que é
a repetição (redundância de dados) e a desorganização deles.
Imagine um campo telefone que permita a entrada de mais de um valor (dois números de telefones) por exemplo. Como faríamos uma busca em um dos valores apenas? Mesma coisa em um campo endereço onde as partes não estivessem desmembradas, da seguinte forma:
Rua das Oliveiras, 256, Parque Novo Mundo, São Paulo, SP.
Como seria possível fazer uma busca de todos os clientes que morassem no Parque Novo
Mundo? Ou na cidade de São Paulo? Ou no estado de SP?
Toda tabela precisa obrigatoriamente ser normalizada com a 1FN?
Não. A normalização é um processo corretivo que deve ser aplicado em casos específicos onde o problema for identificado. Tudo irá depender de como a análise dos dados foi feita. De início você terá muita dificuldade em aplicar as regras de normalização e somente o tempo e o acúmulo de experiência farão esse processo ser natural para você. Um analista experiente aplica a normalização de dados por padrão, pois ele olha para uma tabela e já ‘sente’ que tem algo errado ali e aplica a correção para tal.
2ª Forma Normal (2FN): Dependência Total
Para estar na 2FN, a tabela precisa estar na 1FN e todos os atributos não-chave devem depender de toda a chave primária (isso se aplica a tabelas com chaves primárias compostas). Uma entidade estará na 2FN se ela já se encontrar na 1FN e todos os atributos não chave forem totalmente dependentes da chave primária.
- Crie tabelas separadas para conjuntos de valores que se aplicam a vários registros.
- Relacione essas tabelas com uma chave estrangeira.
- Primeiramente, para estar na 2FN é preciso estar também na 1FN.
2FN define que os atributos normais, ou seja, os não chave, devem depender unicamente da chave primária da tabela. Assim como as colunas da tabela que não são dependentes dessa chave devem ser removidas da tabela principal e cria-se uma nova tabela utilizando esses dados.
Problema (1FN, mas viola 2FN): Uma tabela de matrículas onde a chave composta é ID_Aluno + ID_Curso. O Nome_Curso depende apenas do ID_Curso, não do aluno.
| ID_Aluno | ID_Curso | Nome_Curso | Semestre_Matricula |
| 55 | 10 | Banco de Dados | 2026.1 |
| 55 | 20 | Programação | 2026.1 |
Solução (2FN): Separar as informações específicas do curso em uma nova tabela.
Tabela Matricula:
| ID_Aluno | ID_Curso | Semestre_Matricula |
| 55 | 10 | 2026.1 |
| 55 | 20 | 2026.1 |
Tabela Curso:
| ID_Curso | Nome_Curso |
| 10 | Banco de Dados |
| 20 | Programação |
Conforme vimos tanto com a 1FN quanto agora com a 2FN, quando aplicamos a normalização de dados é comum gerar novas tabelas a fim de satisfazer as formas normais que estão sendo aplicadas. Mais uma vez gostaria de deixar claro que a normalização de dados, apesar das regras serem simples, causa grande dificuldade nos iniciantes da área. Então tenha paciência pois com o tempo irá ganhar experiência e tudo ficará mais fácil.
3ª Forma Normal (3FN): Sem Dependências Transitivas
Para estar na 3FN, a tabela deve estar na 2FN e nenhum atributo não-chave pode depender de outro atributo não-chave. Todos devem depender apenas da chave primária.
- Elimine campos que não dependem da chave.
- Assim como para estar na 2FN é preciso estar na 1FN, para estar na 3FN é preciso estar também na 2FN.
3FN define que todos os atributos dessa tabela devem ser funcionalmente independentes uns dos outros, ao mesmo tempo que devem ser dependentes exclusivamente da chave primária da tabela.
3FN foi projetada para melhorar o desempenho de processamento dos banco de dados e minimizar os custos de armazenamento.
Problema (2FN, mas viola 3FN): Uma tabela de veículos onde a chave primária é a Placa. O atributo Pais_Origem_Marca depende da Marca, e não diretamente da Placa.
| Placa | Modelo | Marca | Pais_Origem_Marca |
| ABC-1234 | Civic | Honda | Japão |
| XYZ-9876 | Corolla | Toyota | Japão |
Solução (3FN): Criar uma tabela separada para as marcas.
Tabela Veiculo:
| Placa | Modelo | ID_Marca |
| ABC-1234 | Civic | 1 |
| XYZ-9876 | Corolla | 2 |
Tabela Marca:
| ID_Marca | Nome_Marca | Pais_Origem_Marca |
| 1 | Honda | Japão |
| 2 | Toyota | Japão |
3.5 Forma Normal de Boyce-Codd (BCNF)
Conhecida como “3.5FN”, ela é uma versão mais rigorosa da 3FN. A regra dita que todo determinante deve ser uma chave candidata. Ela resolve anomalias em tabelas que possuem múltiplas chaves candidatas compostas e sobrepostas.
Problema: Uma clínica onde a chave primária é (ID_Paciente + Especialidade). Um médico atende apenas uma especialidade. O Nome_Medico determina a Especialidade, criando uma redundância se o médico mudar de especialidade.
| ID_Paciente | Especialidade | Nome_Medico |
| 99 | Cardiologia | Dr. Marcos |
| 88 | Cardiologia | Dr. Marcos |
Solução (BCNF): Separar a relação do paciente com o médico, e do médico com a especialidade.
Tabela Consulta:
| ID_Paciente | ID_Medico |
| 99 | 500 |
| 88 | 500 |
Tabela Medico_Especialidade:
| ID_Medico | Nome_Medico | Especialidade |
| 500 | Dr. Marcos | Cardiologia |
4ª Forma Normal (4FN): Dependências Multivaloradas Independentes
Para estar na 4FN, a tabela deve estar na BCNF e não pode conter mais de uma dependência multivalorada independente.
Problema: Um programador tem várias “Linguagens” (Python, Java) e possui várias “Certificações” (AWS, Azure). Colocar tudo na mesma tabela cria uma multiplicação (produto cartesiano) de registros desnecessários.
| ID_Programador | Linguagem | Certificacao |
| 1 | Python | AWS |
| 1 | Python | Azure |
| 1 | Java | AWS |
| 1 | Java | Azure |
Solução (4FN): Criar duas tabelas distintas para separar as dependências que não têm relação entre si.
Tabela Programador_Linguagem:
| ID_Programador | Linguagem |
| 1 | Python |
| 1 | Java |
Tabela Programador_Certificacao:
| ID_Programador | Certificacao |
| 1 | AWS |
| 1 | Azure |
5ª Forma Normal (5FN): Dependência de Junção
É extremamente rara na prática. Diz que uma tabela está na 5FN se ela não puder ser dividida em tabelas menores sem perder informações ao tentar juntá-las (JOIN) novamente. Trata de relações ternárias (três variáveis conectadas) que causam anomalias se agrupadas.
Problema: Uma relação complexa onde um Vendedor vende produtos de uma Marca que pertence a uma Categoria. Se juntarmos tudo, podemos inferir erroneamente que um vendedor vende uma categoria de uma marca específica que ele, na verdade, não tem autorização para vender.
| Vendedor | Marca | Categoria |
| Roberto | Samsung | Smartphones |
| Roberto | Samsung | TVs |
Solução (5FN): Dividir a relação ternária em três tabelas binárias (relação de dois em dois).
Tabela Vendedor_Marca:
| Vendedor | Marca |
| Roberto | Samsung |
Tabela Vendedor_Categoria:
| Vendedor | Categoria |
| Roberto | Smartphones |
| Roberto | TVs |
Tabela Marca_Categoria:
| Marca | Categoria |
| Samsung | Smartphones |
| Samsung | TVs |
