Se você já precisou buscar uma informação em uma tabela com milhões de linhas e a consulta demorou minutos (ou até horas) para retornar, você já sentiu na pele a falta de um bom índice. Na Engenharia de Dados e Administração de Bancos de Dados (DBA), os Índices são a principal ferramenta para otimizar a performance de leitura.
A Analogia Clássica: O Índice de um Livro
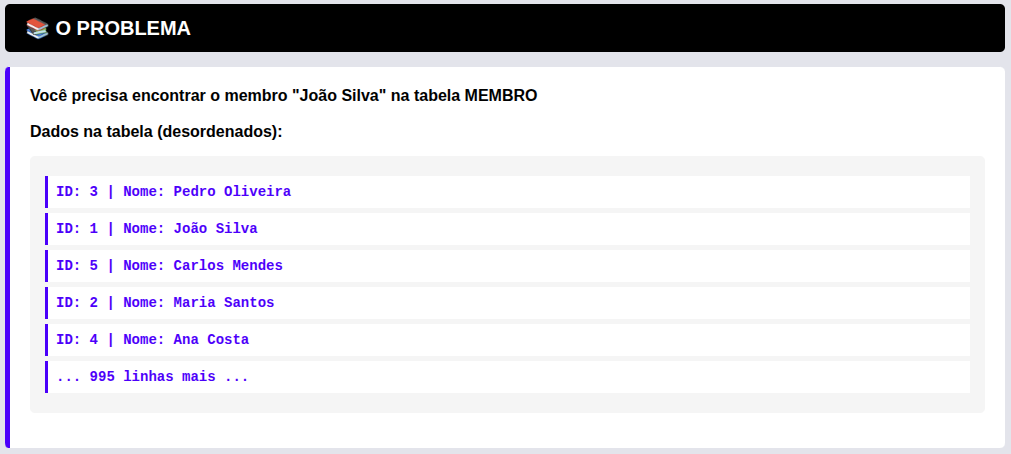
Imagine que você está lendo um livro de História de 1.000 páginas e quer encontrar todas as menções a “Júlio César”.
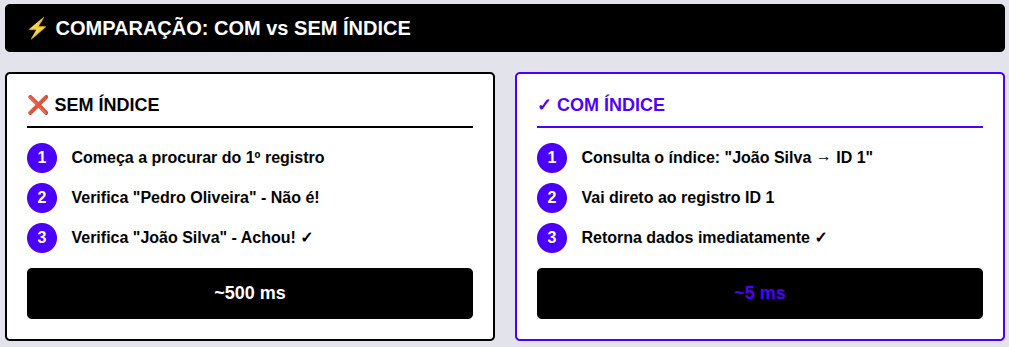
- Sem um índice (Full Table Scan): Você teria que ler o livro inteiro, da página 1 à 1.000, procurando o nome. No banco de dados, isso se chama Full Table Scan (Varredura Completa da Tabela), e é o pior cenário para a performance.
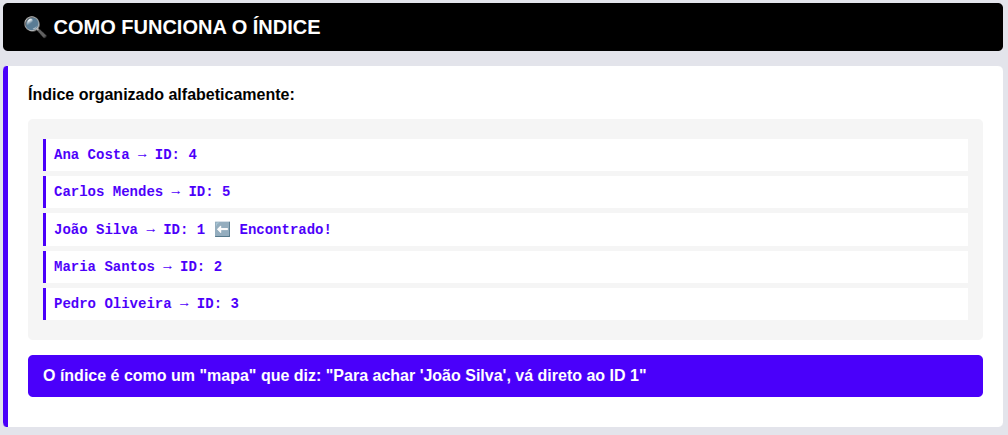
- Com um índice (Index Scan): Você vai até as últimas páginas do livro, no Índice Remissivo, procura a letra “J”, acha “Júlio César” e vê que ele é citado nas páginas 45, 112 e 890. Você vai direto a essas páginas.
Um índice de banco de dados faz exatamente isso: ele cria uma estrutura de dados separada (geralmente uma árvore chamada B-Tree) que mantém os valores de uma coluna específica ordenados, junto com um “ponteiro” (o número da página) que diz exatamente onde a linha inteira está gravada no disco.
O Preço a se Pagar (Trade-offs)
Se os índices deixam tudo mais rápido, por que não colocamos índices em todas as colunas de todas as tabelas?
Porque índices não são mágicos; eles têm um custo.
- Overhead de Escrita (Lentidão no CRUD): Toda vez que você faz um
INSERT,UPDATEouDELETEna tabela, o banco de dados precisa atualizar a tabela principal E reorganizar a estrutura do índice. Muitos índices deixam as gravações muito lentas. - Consumo de Disco: O índice é uma cópia ordenada dos dados daquela coluna. Ele ocupa espaço físico no servidor. Um banco de dados super indexado pode ter seus índices ocupando mais gigabytes do que os próprios dados reais.
Quando Usar (e Quando NÃO Usar) Índices
A arte da otimização de banco de dados está em saber equilibrar a balança entre a velocidade de leitura e o custo de escrita.
Onde você DEVE criar índices:
- Chaves Primárias (PK) e Estrangeiras (FK): (Bancos relacionais geralmente criam o índice da PK automaticamente). Essencial para que os
JOINsentre tabelas sejam rápidos. - Colunas muito usadas no
WHERE: Se você pesquisa clientes pelo CPF o tempo todo, a colunacpfprecisa de um índice. - Colunas usadas em
ORDER BYouGROUP BY: Como o índice já guarda os dados de forma ordenada, o banco não gasta processamento extra para ordenar o resultado.
Onde você NÃO DEVE criar índices:
- Tabelas muito pequenas: Se a tabela tem 500 linhas, o banco lê tudo em milissegundos. O índice só gastaria espaço.
- Colunas de Baixa Cardinalidade: Colunas com poucos valores distintos, como
sexo(M/F) oustatus(Ativo/Inativo). O índice não ajuda a filtrar muita coisa e o banco pode acabar optando pelo Full Table Scan de qualquer jeito. - Tabelas com altíssimo volume de inserção (Logs): Se uma tabela recebe milhares de
INSERTSpor segundo e é pouco lida, um índice vai criar um gargalo de gravação.
Exemplos Práticos em Código SQL
Vamos ver como aplicar isso na prática usando SQL. Imagine uma tabela Clientes com milhões de registros.
1. Criando um Índice Simples
Se o time de vendas sempre busca clientes pelo e-mail, criar um índice nessa coluna vai transformar uma busca que demorava 10 segundos em algo que leva 5 milissegundos.
-- Criando um índice simples na coluna email
CREATE INDEX idx_clientes_email
ON Clientes (email);
2. Criando um Índice Único (Unique Index)
Além de acelerar a busca, ele garante a integridade dos dados, impedindo que dois clientes sejam cadastrados com o mesmo CPF.
-- Criando um índice único na coluna cpf
CREATE UNIQUE INDEX idx_clientes_cpf
ON Clientes (cpf);
3. Criando um Índice Composto (Composite Index)
Se você tem uma consulta que SEMPRE filtra por duas colunas ao mesmo tempo (ex: buscar vendas de uma loja específica em uma data específica), você pode criar um índice que combina as duas colunas.
-- Índice composto: a ordem das colunas importa!
CREATE INDEX idx_vendas_loja_data
ON Vendas (id_loja, data_venda);
(Nota: Esse índice é excelente para consultas como WHERE id_loja = 5 AND data_venda = '2026-03-11', mas não ajudaria em nada se você buscasse APENAS pela data_venda).
4. Removendo um Índice
Se você percebeu que um índice não está sendo usado e está apenas atrasando suas inserções, você deve excluí-lo.
-- Removendo o índice do banco de dados
DROP INDEX idx_clientes_email;
DataWarehouses Modernos não utilizam índices tradicionais.
Bancos de dados tradicionais (OLTP) usam índices B-Tree para encontrar uma agulha no palheiro (uma linha específica). Já o BigQuery e o Snowflake são bancos Orientados a Colunas (Columnar Databases) projetados para análise massiva de dados (OLAP).
Em vez de índices, eles usam três conceitos automáticos:
- Micro-particionamento (Automático): No Snowflake, por exemplo, os dados são divididos em arquivos minúsculos chamados micro-partitions. O sistema sabe o valor mínimo e máximo de cada coluna em cada arquivo e descarta o que não precisa ler.
- Metadata Cache: O banco mantém metadados sobre onde cada dado está. Ele não precisa de você para “criar” o caminho; ele faz isso sozinho.
- Clustering: É o “primo” do índice nessas ferramentas. Você define uma
Clustering Keypara dizer ao banco: “Organize esses dados fisicamente por data e região”. Isso agrupa os dados de forma eficiente.
Como saber se uma tabela tem “índices” (ou otimizações) em Data Warehouses modernos
Se você está em um banco tradicional, você procura por Indexes. Se você está em BigQuery/Snowflake, você procura por Clustering e Partitioning.
1. No Snowflake
O Snowflake não tem índices. Se você quer saber como uma tabela foi otimizada, você deve checar as Clustering Keys.
- Via interface: Vá na aba “Data”, selecione a tabela e procure por “Clustering Information”.
- Via código SQL:
-- Mostra detalhes da tabela, incluindo as chaves de agrupamento (clustering)
SHOW TABLES LIKE 'nome_da_minha_tabela';
-- Verifique a coluna 'cluster_by' no resultado.
2. No BigQuery
O BigQuery usa Partitioning (geralmente por data) e Clustering.
- Via interface: Clique na tabela e vá na aba “Details”. Procure pelas seções “Table info” (onde diz se é particionada) e “Schema” (onde as colunas de cluster aparecem com um ícone específico).
- Via código SQL:
-- Consulta os metadados das tabelas no dataset
SELECT table_name, ddl
FROM `meu_projeto.meu_dataset.INFORMATION_SCHEMA.TABLES`
WHERE table_name = 'nome_da_tabela';
-- No DDL (o código de criação), você verá as cláusulas PARTITION BY e CLUSTER BY.
3. Em Bancos Tradicionais (Postgres, SQL Server, MySQL)
Se você cair em um projeto que usa bancos relacionais comuns, você usa as tabelas de sistema:
-- Exemplo para PostgreSQL: Lista todos os índices de uma tabela
SELECT * FROM pg_indexes WHERE tablename = 'nome_da_tabela';
-- Exemplo genérico (muitas ferramentas de BI mostram isso na lateral):
-- Procure por uma pasta chamada "Indexes" na árvore de objetos do banco.
Dica para Arquitetos e Engenheiros
Índices são a ponte entre um sistema que “funciona” e um sistema que escala. Em um curso de Engenharia de Dados, esse tema é o divisor de águas que ensina os alunos a pararem de culpar o “servidor fraco” e começarem a olhar para a estrutura física das suas consultas.
