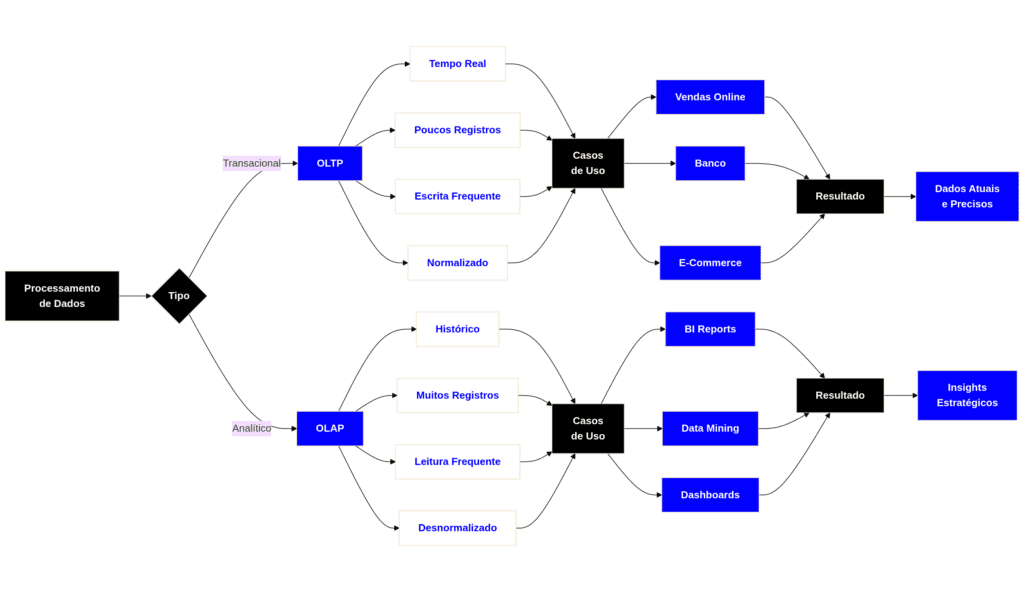
A distinção entre OLTP (Online Transaction Processing) e OLAP (Online Analytical Processing) é a pedra angular da arquitetura de dados moderna.
Compreenda que sistemas de software possuem necessidades antagônicas: alguns precisam registrar eventos unitários em tempo real com garantia de integridade (escrita rápida), enquanto outros precisam processar milhões de registros para gerar insights (leitura massiva).
Tentar resolver ambos os problemas com uma única arquitetura resulta em gargalos de performance e travamentos sistêmicos.
Diferenças Fundamentais: OLTP vs. OLAP
Considere o seguinte cenário hipotético para ilustrar a dicotomia:
Imagine um grande supermercado:
- Cenário A (OLTP): O caixa registra a compra de um cliente. O sistema precisa descontar 1 item do estoque, criar 1 registro de venda e emitir a nota fiscal. Isso deve ocorrer em milissegundos. Se o sistema travar, a fila para.
- Cenário B (OLAP): O gerente regional quer saber “Qual foi a marca de sabão em pó mais vendida nas terças-feiras chuvosas dos últimos 5 anos?”. O sistema precisa ler milhões de linhas de histórico, agrupar por data e produto e somar os valores.
Misturar o Cenário B no banco de dados do Cenário A faria o caixa travar enquanto o relatório é gerado. Por isso, separamos os ambientes.
Definições Técnicas
Sob a ótica da Engenharia de Dados, essas siglas definem não apenas o uso, mas a estrutura física de armazenamento e modelagem dos dados.
OLTP (Online Transaction Processing)
Sistemas projetados para processar um grande número de transações curtas e atômicas em tempo real. O foco é a integridade dos dados e a velocidade de inserção/atualização.
- Característica de Armazenamento: Orientado a Linha (Row-oriented).
- Propriedade Chave: Segue rigorosamente as propriedades ACID (Atomicidade, Consistência, Isolamento, Durabilidade).
- Estado dos Dados: Dados atuais, voláteis e altamente normalizados (para evitar redundância).
OLAP (Online Analytical Processing)
Sistemas projetados para consultas complexas, agregações e análise de grandes volumes de dados históricos. O foco é a performance de leitura (Scan).
- Característica de Armazenamento: Orientado a Coluna (Columnar).
- Propriedade Chave: Otimizado para operações de Select, Group By e funções de agregação (Sum, Avg).
- Estado dos Dados: Dados históricos, imutáveis (geralmente) e desnormalizados (para evitar joins excessivos).
Qual a Importância Desse Conceito?
A segregação entre OLTP e OLAP é vital para a escalabilidade e estabilidade de qualquer ecossistema de dados.
- Isolamento de Carga: Impede que um analista de dados, ao rodar uma consulta pesada, derrube o sistema de produção que atende o cliente final.
- Otimização de Hardware: Servidores OLTP precisam de muita RAM e disco rápido (IOPS) para escritas aleatórias. Servidores OLAP precisam de CPUs potentes e banda larga de disco para varredura sequencial.
- Modelagem Adequada: Permite usar modelagem normalizada (3NF) na origem para garantir consistência e modelagem dimensional (Star Schema) no destino para facilitar o uso por humanos e ferramentas de BI.
Exemplos Práticos Reais
Observe como empresas utilizam essa divisão na prática:
| Setor | Aplicação OLTP (Transacional) | Aplicação OLAP (Analítico) |
| Bancário | Transferência PIX, pagamento de boleto, atualização de saldo em tempo real. | Análise de risco de crédito, detecção de padrões de fraude, relatórios de lucratividade por agência. |
| E-commerce | Inserção de pedido no carrinho, atualização de status de entrega, cadastro de cliente. | Recomendação de produtos baseada em histórico, cálculo de LTV (Lifetime Value), análise de churn. |
| Logística | Rastreamento de pacote em tempo real (GPS), alocação de motorista. | Otimização de rotas baseada em dados históricos de trânsito, análise de eficiência de frota. |
Principais Métodos de Implementação
A implementação difere drasticamente na forma como os dados são modelados e acessados.
Modelagem OLTP: Normalização (3NF)
O objetivo é eliminar redundância. Se o nome de um cliente muda, você altera em apenas um lugar.
- Vantagem: Escrita rápida, consistência garantida, banco de dados compacto.
- Desvantagem: Leituras lentas pois exigem muitos JOINS complexos.
Modelagem OLAP: Modelagem Dimensional (Kimball)
O objetivo é facilitar a consulta. Utiliza-se esquemas como Star Schema ou Snowflake.
- Tabela Fato: Contém as métricas (números) e chaves estrangeiras (Ex: Vendas).
- Tabelas Dimensão: Contém o contexto descritivo (Ex: Quem vendeu, Onde, Quando).
- Vantagem: Leitura extremamente rápida, SQL mais simples.
- Desvantagem: Redundância de dados, escrita mais lenta (ETL/ELT necessário).
Exemplo de Código Comparativo (SQL)
Observe a complexidade da consulta para obter o mesmo resultado:
-- OLTP (Muitos Joins necessários devido à normalização)
SELECT c.region_name, SUM(o.total_amount)
FROM orders o
JOIN customers cu ON o.customer_id = cu.id
JOIN addresses a ON cu.address_id = a.id
JOIN cities ci ON a.city_id = ci.id
JOIN regions c ON ci.region_id = c.id
WHERE o.order_date >= '2023-01-01'
GROUP BY c.region_name;
-- OLAP (Tabela desnormalizada ou Star Schema)
SELECT region_name, SUM(total_amount)
FROM fct_sales
JOIN dim_location ON fct_sales.location_sk = dim_location.location_sk
WHERE date_key >= 20230101
GROUP BY region_name;
Principais Tecnologias Utilizadas
Não utilize a ferramenta errada para o trabalho. Escolha a tecnologia baseada na arquitetura.
| Categoria | Tecnologias Líderes | Características |
| OLTP (RDBMS) | PostgreSQL, MySQL, Oracle Database, SQL Server, AWS Aurora. | Otimizados para row-store, índices B-Tree, alta concorrência de escrita. |
| OLAP (Data Warehouse) | Snowflake, Google BigQuery, AWS Redshift, Databricks SQL, ClickHouse. | Otimizados para column-store, compressão massiva, processamento paralelo massivo (MPP). |
Nota Arquitetural: Hoje, o conceito de Lakehouse (Databricks, Delta Lake, Apache Iceberg) tenta unir o melhor dos dois mundos, permitindo transações ACID sobre arquivos em Object Storage, mas a distinção lógica entre processamento transacional e analítico permanece.
7. Principais Desafios e Considerações Gerais
Ao projetar essas soluções, atente-se aos seguintes pontos de atrito:
- Latência de Dados (Data Latency): Existe um tempo (delay) entre o dado ser gerado no OLTP e estar disponível no OLAP. Processos Batch (D-1) são comuns, mas o negócio exige cada vez mais Near Real-Time (Streaming).
- Evolução de Schema (Schema Drift): Se o desenvolvedor altera uma coluna no OLTP, isso pode quebrar o pipeline de ETL que alimenta o OLAP. O acoplamento deve ser gerenciado.
- Custo de Armazenamento e Computação: Bancos OLAP modernos (Cloud) cobram por dados escaneados ou tempo de computação. Consultas mal escritas em tabelas desnormalizadas podem custar milhares de dólares.
8. Melhores Práticas de Mercado
Para garantir uma arquitetura robusta, adote as seguintes diretrizes:
- Réplicas de Leitura (Read Replicas): Nunca conecte uma ferramenta de BI diretamente no banco OLTP principal (Master). Se precisar fazer análises leves em tempo real, crie uma réplica de leitura do banco transacional.
- CDC (Change Data Capture): Utilize ferramentas de CDC (como Debezium ou DMS) para replicar dados do OLTP para o OLAP lendo o log de transações do banco, em vez de fazer consultas pesadas de
SELECT *periodicamente. - Compressão Colunar: No OLAP, certifique-se de que as tabelas estejam armazenadas em formatos colunares (Parquet, ORC) ou nativos do DW, pois a compressão é muito superior, economizando custo e I/O.
- Particionamento: Particione suas tabelas OLAP (geralmente por data). Isso permite que o motor de consulta ignore blocos de dados irrelevantes (partition pruning), acelerando drasticamente a leitura.
