Compreenda a distinção fundamental:
- Concorrência é sobre a composição de processos independentes (lidar com múltiplas coisas ao mesmo tempo).
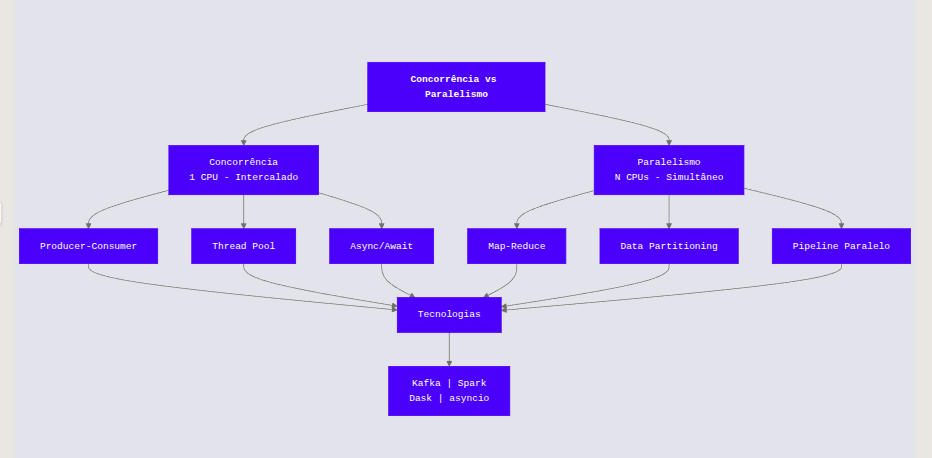
- Paralelismo é sobre a execução simultânea (fazer múltiplas coisas ao mesmo tempo). Um sistema pode ser concorrente sem ser paralelo (ex: um único núcleo de CPU alternando tarefas), mas o paralelismo real exige hardware capaz de multitarefa simultânea.
Concorrência e Paralelismo sob diferentes óticas
Sob a Ótica da Engenharia de Software
Na programação de aplicações, a Concorrência resolve problemas de latência e responsividade. Ocorre quando duas ou mais tarefas podem iniciar, rodar e completar em períodos de tempo sobrepostos.
O sistema operacional utiliza o Context Switching (troca de contexto) para alternar o uso da CPU entre tarefas, criando a ilusão de simultaneidade.
O Paralelismo ocorre quando tarefas são literalmente executadas no mesmo instante físico, exigindo arquiteturas Multi-Core.
Sob a Ótica da Engenharia de Dados
Na Engenharia de Dados, a escala muda de uma única máquina para clusters distribuídos.
- Concorrência em Dados: Refere-se à capacidade de um orquestrador (como o Airflow) gerenciar centenas de DAGs (Directed Acyclic Graphs) ativos. O scheduler decide qual task deve ser enviada para a fila, lidando com dependências e prioridades, mesmo que não haja slots suficientes para rodar tudo instantaneamente.
- Paralelismo em Dados: Refere-se ao processamento distribuído (ex: Apache Spark ou Databricks). Um arquivo de 1TB é dividido em 1000 partições. 1000 núcleos de CPU (espalhados por vários nós) processam essas partições exatamente ao mesmo tempo. É a base do paradigma MPP (Massively Parallel Processing).
Qual a sua importância?
A aplicação correta destes conceitos não é apenas uma questão de velocidade, mas de robustez sistêmica e eficiência econômica.
Tolerância a Falhas e Isolamento
Sistemas concorrentes bem projetados isolam falhas. Se você processa 1 milhão de registros em um único loop sequencial e o registro 999.000 falha, todo o processo para.
Ao utilizar concorrência, cada “worker” opera de forma independente. Se um falha, apenas aquela unidade de trabalho é perdida ou reprocessada (retry), sem derrubar todo o pipeline.
Consistência de Dados
Em ambientes concorrentes, múltiplos processos podem tentar ler ou escrever o mesmo dado (Race Condition). Mecanismos de controle de concorrência (como Locks, semáforos ou controle via MVCC – Multiversion Concurrency Control em bancos de dados) garantem que transações financeiras ou atualizações de estoque mantenham as propriedades ACID, impedindo corrupção de dados.
Redução de Custos Operacionais
- Recursos Ociosos: Processos sequenciais frequentemente deixam CPU ociosa enquanto esperam I/O (leitura de disco/rede). A concorrência preenche esses vazios com outras tarefas, maximizando o uso do hardware alugado na nuvem.
- Tempo de Cluster: O paralelismo reduz o tempo total de execução (wall-clock time). Em nuvem, onde você paga por “segundo de cluster ligado”, reduzir um job de 10 horas para 1 hora (usando 10x mais máquinas) custa teoricamente o mesmo, mas entrega valor ao negócio muito mais rápido.
Exemplo Prático Real (Engenharia de Dados)
Cenário: Uma empresa de logística recebe telemetria de 50.000 caminhões a cada 30 segundos. O objetivo é ingerir, limpar e armazenar esses dados no Data Lake.
| Abordagem Sem Concorrência/Paralelismo (O Erro) | Abordagem Ideal (A Solução) |
|---|---|
| Um script Python simples lê a fila de mensagens (Kafka), processa um JSON por vez e salva no S3. Resultado: O script processa 50 mensagens/segundo. A entrada é de 1.600 mensagens/segundo. Consequência: Latência acumulada. Dados chegam com horas de atraso (Backlog). Se o script quebrar, o processamento para totalmente. Custo alto de oportunidade. | Implementação de um job Spark Streaming (Paralelismo) com leitura de múltiplos tópicos (Concorrência). Paralelismo de Dados: O Kafka é particionado em 50 partições. O Spark sobe 50 executores, cada um lendo uma partição simultaneamente. Concorrência de I/O: Enquanto os dados são escritos no S3 (operação lenta de rede), a CPU já está desserializando o próximo lote de JSONs. Resultado: Processamento de 10.000 mensagens/segundo. Consequência: Ingestão Near Real-Time. Se um nó do cluster cair, o Spark reage (concorrência de tarefas) e realoca a partição para outro nó. |
Principais Métodos de Implementação
Analise a tabela abaixo para compreender as diferenças de implementação técnica:
| Método | Tipo Principal | Uso Ideal na Eng. de Dados | Limitação Crítica |
|---|---|---|---|
| Multithreading | Concorrência (I/O Bound) | Chamadas de API, Leitura/Escrita de arquivos, requisições HTTP. | GIL (Global Interpreter Lock) no Python impede uso real de múltiplos núcleos para CPU. |
| Multiprocessing | Paralelismo (CPU Bound) | Transformações pesadas locais (Pandas), regex complexo em máquina única. | Alto overhead de memória (cada processo tem seu próprio espaço de memória). |
| Processamento Distribuído | Paralelismo de Cluster | Processamento de Big Data (Spark, Dask, Trino). | Latência de rede (Network Shuffle) e complexidade de gestão de cluster. |
| Async I/O | Concorrência (Event Loop) | Microsserviços de alta vazão, scrapers de dados massivos. | Complexidade de código (“Callback hell”) e difícil depuração. |

Exemplo de Código: Threading vs Multiprocessing (Python)
import time
import threading
import multiprocessing
# Simulação de tarefa I/O Bound (Ex: Request API)
def task_io():
time.sleep(1)
# Simulação de tarefa CPU Bound (Ex: Cálculo Hash)
def task_cpu():
sum([i**2 for i in range(10**6)])
# Implemente Threading para I/O (Concorrência)
# Útil para quando o gargalo é esperar resposta externa
t1 = threading.Thread(target=task_io)
t2 = threading.Thread(target=task_io)
t1.start(); t2.start() # Iniciam "juntas"
# Implemente Multiprocessing para CPU (Paralelismo Real)
# Útil para cálculos pesados que travam a CPU
p1 = multiprocessing.Process(target=task_cpu)
p2 = multiprocessing.Process(target=task_cpu)
p1.start(); p2.start() # Rodam em núcleos diferentes
Desafios e Considerações
- Race Conditions (Condições de Corrida): Ocorrem quando a saída depende da sequência ou tempo de outros eventos incontroláveis. Em ETLs, isso gera dados duplicados ou inconsistentes.
- Deadlocks: O Processo A espera o recurso do Processo B, e o Processo B espera o recurso do Processo A. O sistema trava indefinidamente.
- Complexidade de Debug: Erros em sistemas paralelos são frequentemente não-determinísticos. Um bug pode aparecer apenas 1 vez a cada 100 execuções (“Heisenbugs”), dificultando a reprodução.
Melhores Práticas
Siga estas 5 diretrizes para mitigar riscos ao implementar concorrência e paralelismo:
- Arquitetura “Shared Nothing” (Nada Compartilhado): Projete tarefas que não compartilhem estado (memória ou variáveis globais). Cada worker deve receber seus dados, processar e salvar o resultado sem precisar “conversar” com outros workers. Isso elimina Locks complexos.
- Idempotência é Obrigatória: Garanta que, se uma tarefa paralela falhar e for reexecutada (concorrência), o resultado final seja o mesmo. Use chaves primárias ou upserts ao invés de append cego.
- Prefira Imutabilidade: Dados imutáveis não sofrem de Race Conditions porque não são alterados, apenas lidos. Crie novas tabelas/arquivos ao invés de atualizar os existentes (Write-Once-Read-Many).
- Use Ferramentas de Alto Nível: Evite gerenciar threads e locks manualmente em Python se possível. Utilize frameworks que abstraem essa complexidade, como Apache Spark ou Dask, que gerenciam a distribuição e tolerância a falhas nativamente.
- Particionamento Inteligente: O paralelismo só funciona se os dados puderem ser divididos uniformemente (evite Data Skew). Garanta que suas chaves de partição distribuam o volume de dados de forma equilibrada entre os nós.
