Em sistemas modernos, raramente uma aplicação vive sozinha. Um e-commerce precisa avisar o sistema de logística quando um pedido é pago. Um repositório no GitHub precisa disparar um pipeline de CI/CD a cada novo commit. Uma plataforma de pagamento precisa informar o backend de uma loja sobre estornos. Em todos esses cenários, há uma pergunta central: como um sistema avisa outro de que algo aconteceu, no exato momento em que aconteceu, sem que o segundo precise ficar perguntando?
A resposta, na maior parte dos casos, é webhook.
Webhook é um mecanismo de comunicação entre sistemas no qual uma aplicação envia automaticamente uma requisição HTTP para uma URL pré-configurada quando um evento de interesse ocorre.
Diferente de uma API tradicional, em que o cliente pergunta (“o que há de novo?”), o webhook inverte a lógica: o servidor avisa (“aconteceu isto agora”). Por essa razão, são frequentemente chamados de reverse APIs ou HTTP callbacks.
Por que os webhooks foram criados
Para entender o porquê dos webhooks, é preciso olhar para o problema que eles resolvem: o polling.
Antes da popularização dos webhooks, quando uma aplicação A precisava saber sobre eventos da aplicação B, a única opção viável sobre HTTP era o polling, ou seja, fazer requisições periódicas a um endpoint perguntando “tem novidade?”. Polling funciona, mas é ineficiente em vários eixos:
- Custo computacional: a maioria das requisições de polling retorna vazia, gerando carga em servidores e clientes sem necessidade.
- Latência: se o polling acontece a cada 5 minutos, o evento pode levar até 5 minutos para ser percebido.
- Largura de banda: mesmo respostas vazias consomem rede.
- Escalabilidade: quanto mais clientes fazendo polling, maior a carga sobre o servidor consultado.
O termo “webhook” foi cunhado em 2007 por Jeff Lindsay, num post chamado “Web hooks to revolutionize the web”. A proposta era simples: já que estamos na web e usamos HTTP para tudo, por que não permitir que um serviço chame um endpoint HTTP do outro lado quando algo acontece? O nome vem da ideia de “ganchos” (hooks) na web, pontos onde se pode pendurar um comportamento personalizado.
A partir desse momento, plataformas como GitHub, Stripe, Twilio, Slack e Shopify adotaram webhooks como cidadão de primeira classe em suas APIs, e o padrão se tornou ubíquo.
Como funcionam tecnicamente
API = você pergunta
- Você vai em um restaurante e pergunta ao garçom: “Tem sopa hoje?”
- O garçom responde: “Sim, tem.”
- Você pergunta quando quer saber. Você faz várias perguntas até conseguir o que precisa.
Webhook = eles avisam
- Você se cadastra em um restaurante para receber notificações.
- Quando chega sopa nova, eles ligam para você dizendo: “Chegou sopa!”
- Você não precisa perguntar. Eles avisam automaticamente.
API:
- Seu código: “Stripe, qual é o status desse pagamento?”
- Stripe: “Aguardando”
- Seu código: (espera 1 minuto)
- Seu código: “Stripe, qual é o status desse pagamento?”
- Stripe: “Confirmado!”
Webhook:
- Pagamento é confirmado
- Stripe: (liga para você automaticamente) “Ei, um pagamento foi confirmado!”
- Seu código: processa a notificação
Em uma frase:
- API = você chama quando precisa
- Webhook = eles chamam quando algo acontece
O fluxo básico de um webhook envolve três atores: o produtor (sistema que gera o evento), o consumidor (sistema interessado no evento) e a rede HTTP entre eles.
- O consumidor expõe uma URL pública e configura essa URL no produtor geralmente em um painel administrativo ou via API. Pode também especificar quais tipos de evento deseja receber.
- Quando um evento ocorre dentro do produtor (por exemplo, um pagamento confirmado), ele monta uma requisição HTTP normalmente um
POSTcom payload JSON descrevendo o evento. - O produtor envia essa requisição para a URL configurada.
- O consumidor processa o payload, faz o que precisa fazer (atualiza banco, dispara mensagem, etc.) e responde com um código HTTP de sucesso (geralmente
2xx). - Se o consumidor responder com erro ou não responder dentro de um timeout, o produtor tipicamente faz retentativas com backoff exponencial.

Um payload típico de webhook tem mais ou menos esta cara:
{
"id": "evt_1Q9aB2C3d4E5f6G7",
"type": "payment.succeeded",
"created": 1761360000,
"data": {
"amount": 4990,
"currency": "brl",
"customer_id": "cus_abc123"
}
}Simples por fora, mas há sutilezas importantes segurança, idempotência, ordenação que aparecem rapidamente em produção.
Webhooks na perspectiva de desenvolvimento de software
Para times de desenvolvimento de software, webhooks são a cola que permite construir integrações reativas com baixo acoplamento. Em vez de o sistema A precisar conhecer os detalhes internos do sistema B, basta que B exponha eventos e A se inscreva neles.
Alguns padrões e casos de uso típicos:
Integrações com plataformas de pagamento. O Stripe é o exemplo canônico. Quando uma cobrança é criada, paga, estornada ou falha, ele dispara webhooks como charge.succeeded, charge.failed ou customer.subscription.deleted. O backend da loja escuta esses eventos para atualizar o status do pedido, liberar acesso a um produto digital, enviar e-mail de confirmação ou cancelar uma assinatura. Tentar manter esse estado via polling seria absurdo pagamentos precisam ser refletidos em segundos, não minutos.
Automação a partir de repositórios de código. GitHub, GitLab e Bitbucket disparam webhooks em eventos como push, pull_request, criação de issue e comentários. Sistemas de CI/CD são acionados por esses webhooks. Se o webhook não existisse, cada CI precisaria ficar perguntando “tem commit novo?” para cada repositório monitorado completamente impraticável em escala.
Bots e integrações em ferramentas de comunicação. Slack, Discord e Microsoft Teams oferecem webhooks tanto de entrada (postar mensagens via HTTP) quanto de saída (notificar sistemas externos quando algo acontece num canal). É como bots de status de produção, alertas de monitoramento e notificações de deploy chegam no canal certo no momento certo.
E-commerce e marketplaces. Shopify, Mercado Livre e VTEX usam webhooks para notificar lojistas sobre novos pedidos, mudanças de estoque e devoluções. Sistemas de ERP, fulfillment e atendimento ao cliente consomem esses eventos para manter estados sincronizados.
Telecomunicações e mensageria. Twilio e provedores de WhatsApp Business avisam via webhook sobre status de entrega de SMS, respostas a mensagens e chamadas recebidas permitindo construir fluxos conversacionais em tempo real.
Do ponto de vista arquitetural, webhooks empurram o desenvolvedor para uma mentalidade orientada a eventos. Em vez de pensar “preciso buscar dados periodicamente”, passa-se a pensar “preciso reagir quando isso acontecer”. Isso aproxima sistemas web tradicionais de padrões como event-driven architecture, pub/sub e CQRS sem exigir, no entanto, infraestrutura de mensageria dedicada.
Webhooks na perspectiva de engenharia de dados
Para engenheiros de dados, webhooks têm um papel diferente, mas igualmente central: são uma fonte primária de dados em tempo quase real, e um substituto leve para mecanismos clássicos de Change Data Capture (CDC) ou ingestão batch.
Pipelines tradicionais de dados eram, e em grande parte ainda são, baseados em ETL agendado extrações que rodam a cada hora ou diariamente, lendo tabelas inteiras ou deltas de bancos transacionais. Esse modelo tem dois problemas conhecidos: a latência (dados ficam stale entre execuções) e o custo (extrações pesadas e janelas de manutenção).
Webhooks oferecem uma alternativa para parte desses casos. Quando um sistema externo expõe eventos via webhook, o pipeline de dados pode receber cada evento individualmente, em segundos, e tratá-lo como um registro a ser ingerido no data lake ou no data warehouse.
Alguns padrões comuns:
Ingestão de eventos para data lake. Um endpoint de webhook recebe payloads de Stripe, Segment, Intercom ou outras SaaS, valida assinatura e despeja o JSON cru num bucket S3 (ou GCS, ou ADLS), particionado por data e tipo de evento.
A partir daí, ferramentas como dbt, Spark ou Snowflake transformam esses eventos em modelos analíticos. Esse padrão é a base do que ferramentas como Fivetran, RudderStack e Segment fazem por baixo dos panos.
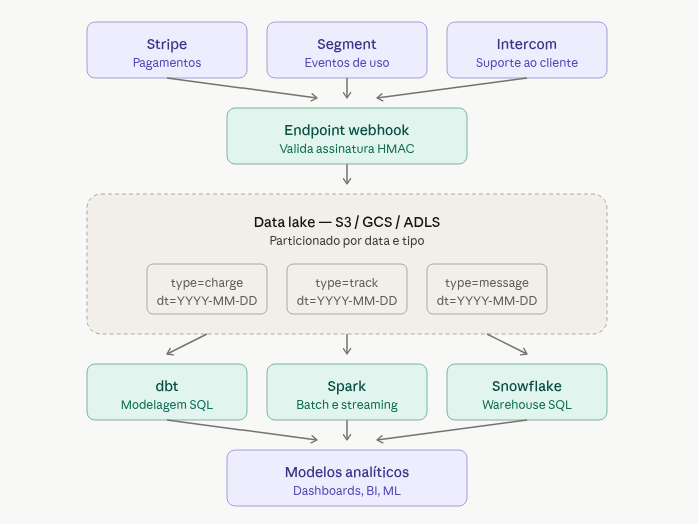
Disparo de pipelines. Webhooks também funcionam como gatilhos de orquestração. Um arquivo aparece num bucket → o serviço de storage dispara um webhook → o Airflow ou o Prefect inicia um DAG que processa o arquivo. Sistemas como AWS EventBridge, Azure Event Grid e Google Eventarc são, em essência, infraestrutura industrial em torno desse padrão.
Sincronização entre sistemas operacionais e analíticos. Em vez de replicar um banco transacional inteiro toda noite, a aplicação emite webhooks a cada mudança relevante (order.created, user.updated, inventory.changed). O pipeline de dados consome esses eventos e mantém o warehouse atualizado em near real-time. Essa abordagem se aproxima de event sourcing, e é uma alternativa interessante quando CDC direto no banco é difícil ou caro.
Alimentação de feature stores e modelos de ML. Eventos de comportamento do usuário capturados via webhook podem alimentar feature stores online, permitindo que modelos de recomendação ou detecção de fraude operem com dados frescos.
O cuidado, do lado de dados, é que webhooks introduzem desafios específicos: eventos podem chegar fora de ordem, podem ser duplicados, podem ser perdidos se o consumidor cair, e podem chegar em volumes altíssimos durante picos.
Por isso, na prática, raramente o handler de webhook escreve direto no warehouse. O padrão maduro é: o handler valida o evento, escreve em uma fila durável (Kafka, SQS, Pub/Sub) e responde 200 rapidamente. Daí em diante, o pipeline trata o evento com as garantias necessárias idempotência, ordenação por chave, dead-letter queues para falhas persistentes.
Qual é a diferença entre um webook e uma API?
A diferença está em quem inicia a conversa e quando ela acontece.
Uma API tradicional (geralmente REST) funciona por pull: o cliente é quem pergunta. Ele faz uma requisição HTTP quando precisa de algo GET /pedidos/123, POST /usuarios e o servidor responde.
Nada acontece se o cliente não perguntar. É um modelo síncrono e sob demanda: você pede, recebe a resposta naquele momento, e a conversa termina ali.
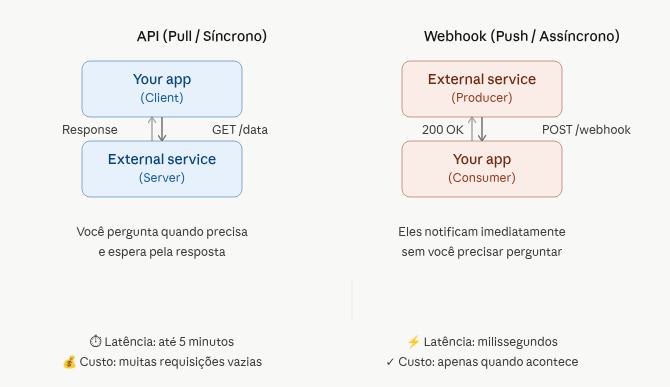
Um webhook funciona por push: o servidor é quem avisa. Quando um evento de interesse acontece (pagamento confirmado, commit recebido, pedido criado), ele dispara uma requisição HTTP para uma URL que você cadastrou previamente. Você não pergunta você é notificado. É assíncrono e orientado a eventos.
Vale notar que webhook não é o oposto de API é um tipo de uso de API. Tecnicamente, ambos são apenas requisições HTTP. A diferença é a direção e o gatilho:
- Numa API tradicional, seu sistema chama o sistema deles quando precisa de informação.
- Num webhook, o sistema deles chama o seu sistema quando algo acontece.
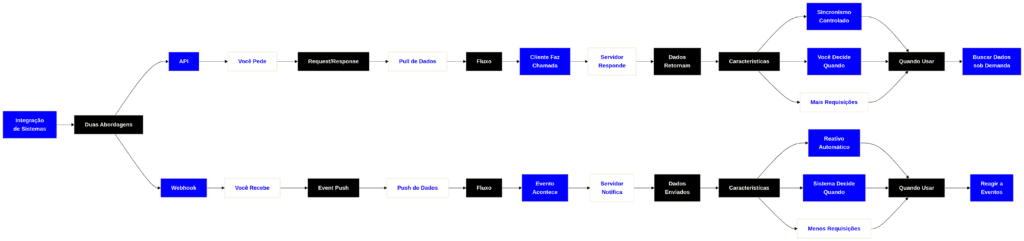
Por isso webhooks são frequentemente descritos como “APIs reversas” ou “callbacks HTTP”.
Um exemplo concreto deixa isso claro. Imagine que você integrou sua loja com o Stripe:
- Via API: você chama
POST /chargespara criar uma cobrança, ouGET /charges/ch_123para consultar o status. A iniciativa é sempre sua. - Via webhook: o Stripe chama o seu endpoint
/stripe-eventsquando o cliente realmente paga, quando uma assinatura é cancelada, quando há um estorno. A iniciativa é deles.
E é por isso que os dois coexistem não competem. APIs servem para você fazer coisas num sistema externo (criar, ler, atualizar, deletar). Webhooks servem para você saber quando coisas acontecem num sistema externo. Numa integração madura com Stripe, GitHub ou Shopify, você usa os dois: a API para agir, o webhook para reagir.
A alternativa ao webhook seria ficar fazendo polling chamar a API a cada poucos segundos perguntando “tem novidade? tem novidade?”. Funciona, mas é caro, lento e desperdiça recursos. O webhook resolve exatamente esse desperdício: em vez de você perguntar mil vezes, o servidor avisa uma vez, no momento exato.
Desafios e boas práticas
Webhooks parecem simples em diagrama, mas em produção exigem disciplina:
- Segurança. Como a URL é pública, qualquer um pode tentar bater nela. Plataformas sérias assinam o payload com HMAC e enviam a assinatura num header (
Stripe-Signature,X-Hub-Signature-256no GitHub). O consumidor recalcula o HMAC com um segredo compartilhado e compara. Sem essa validação, o endpoint vira porta aberta para forjar eventos. - Idempotência. Retentativas e duplicações são parte do ciclo de vida normal. Cada evento traz um ID único, e o consumidor deve registrar esses IDs para descartar reentregas. Sem isso, um cliente pode ser cobrado duas vezes ou um e-mail enviado em duplicidade.
- Tempo de resposta. A maioria das plataformas espera resposta em poucos segundos. Processamento pesado dentro do handler é um anti-padrão o correto é enfileirar e responder rápido.
- Tratamento de falhas. Retries com backoff exponencial são comuns, mas têm limite. Eventos que falham repetidamente vão para dead-letter queues e exigem investigação manual ou reprocessamento programático.
- Observabilidade. Logar todo evento recebido, com ID, tipo e timestamp, é essencial para depurar especialmente porque o produtor controla o tráfego e o consumidor não pode “pedir de novo” facilmente.
- Ordenação. A maioria das plataformas não garante ordem de entrega. Se a ordem importa (e quase sempre importa em dados), o consumidor precisa lidar com isso, geralmente usando timestamps ou números de versão dentro do payload.
Conclusão
Webhooks são, hoje, a forma padrão de dois sistemas em HTTP conversarem em tempo real sem que um precise interrogar o outro. Para times de desenvolvimento, são a base de integrações reativas, automações e arquiteturas orientadas a eventos. Para times de dados, são uma fonte de ingestão near real-time que complementa e em muitos casos substitui pipelines batch tradicionais.
A simplicidade aparente esconde armadilhas reais: segurança, idempotência, ordenação e tratamento de falhas precisam ser pensados desde o início. Mas, dominados esses cuidados, webhooks são uma das ferramentas mais baratas e poderosas para construir sistemas modernos que reagem ao mundo no ritmo em que ele acontece.
