No mundo do Data Warehousing e da modelagem analítica (como o Star Schema de Ralph Kimball), nós dividimos os dados em duas categorias principais: Fatos (os eventos numéricos, como uma venda) e Dimensões (o contexto descritivo, como o Cliente, o Produto ou a Loja).
Enquanto os Fatos acontecem a todo momento (milhares de vendas por minuto), as Dimensões mudam lentamente. Um cliente não muda de nome ou de endereço todos os dias. Porém, quando essa mudança acontece, a Engenharia de Dados precisa decidir como lidar com ela.
Se o João morava em São Paulo em 2025 e se mudou para o Rio de Janeiro em 2026, a venda que ele fez em 2025 deve ser contabilizada para SP ou para o RJ?
É para resolver esse problema de rastreamento histórico que existem as Slowly Changing Dimensions (SCD), ou Dimensões de Alteração Lenta. Os três tipos principais são o SCD Tipo 1, Tipo 2 e Tipo 3.
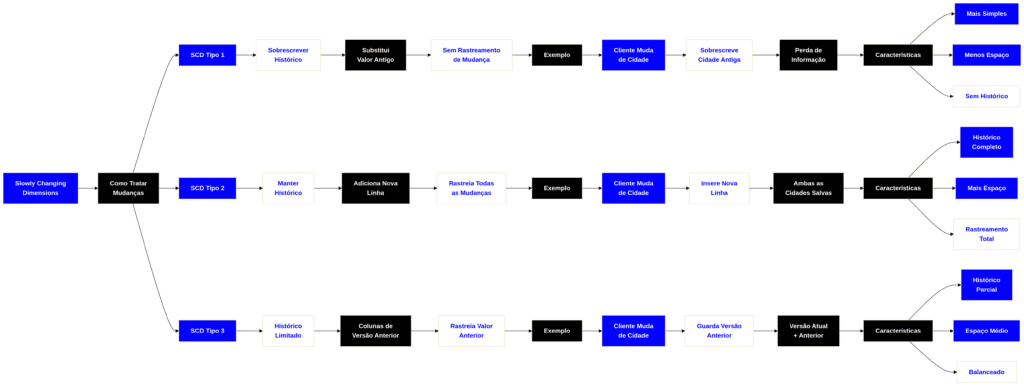
SCD Tipo 1: Substituição Direta (O Esquecimento)
O SCD Tipo 1 é a abordagem mais simples. Quando um dado muda no sistema de origem, você simplesmente sobrescreve o dado antigo no seu banco analítico.
- Objetivo: Ter sempre a informação mais atualizada possível.
- O que acontece com o histórico: Ele é perdido para sempre.
- Quando usar: Quando a mudança for uma correção de erro (ex: nome digitado errado) ou quando o histórico daquela informação não tiver nenhuma importância para as regras de negócio da empresa.
Exemplo Prático:
A cliente “Ana” atualiza seu número de telefone no cadastro.
Tabela Antes:
| ID_Cliente | Nome | Telefone |
| 15 | Ana Silva | (11) 9999-0000 |
Tabela Depois (SCD 1 aplicado):
| ID_Cliente | Nome | Telefone |
| 15 | Ana Silva | (21) 8888-1111 |
Note que não há como saber qual era o telefone antigo da Ana.
SCD Tipo 2: Versionamento (A Máquina do Tempo)
O SCD Tipo 2 é o padrão ouro da Engenharia de Dados corporativa. Quando um atributo muda, você não apaga nada. Em vez disso, você “encerra” a validade do registro antigo e insere uma nova linha na tabela com o dado atualizado.
Para que isso funcione, a tabela ganha novas colunas de controle, geralmente: Data_Inicio, Data_Fim e Status_Atual (Ativo/Inativo), além de uma Surrogate Key (Chave Artificial) para diferenciar as versões da mesma pessoa.
- Objetivo: Manter o histórico completo e preciso de todas as mudanças.
- O que acontece com o histórico: É totalmente preservado. Relatórios do passado puxarão os dados exatamente como eram na época.
- Quando usar: Quando o rastreamento histórico for essencial para auditoria, relatórios financeiros ou análises temporais (ex: mudança de cargo de um funcionário, mudança de endereço de um cliente).
Exemplo Prático:
O cliente “Carlos” morava em São Paulo, mas no dia 09/04/2026 ele se mudou para o Rio de Janeiro.
Tabela Antes:
| SK_Cliente | ID_Cliente | Nome | Estado | Data_Inicio | Data_Fim | Ativo |
| 1001 | 42 | Carlos | SP | 2022-01-01 | NULL | Sim |
Tabela Depois (SCD 2 aplicado):
| SK_Cliente | ID_Cliente | Nome | Estado | Data_Inicio | Data_Fim | Ativo |
| 1001 | 42 | Carlos | SP | 2022-01-01 | 2026-04-09 | Não |
| 1002 | 42 | Carlos | RJ | 2026-04-09 | NULL | Sim |
Se o analista pedir as vendas do Carlos em 2025, o sistema fará um JOIN com a linha SK_Cliente 1001 (SP). Se pedir as vendas de hoje, usará a linha 1002 (RJ).
SCD Tipo 3: Nova Coluna (A História Parcial)
O SCD Tipo 3 é um meio-termo. Ele mantém o histórico, mas apenas da versão imediatamente anterior. Em vez de adicionar uma nova linha (como no Tipo 2), você adiciona uma nova coluna à tabela atual para guardar o valor antigo.
- Objetivo: Permitir a comparação rápida entre o estado atual e o estado anterior sem aumentar o número de linhas da tabela.
- O que acontece com o histórico: Você retém apenas 1 nível de passado. Se o dado mudar uma terceira vez, o histórico mais antigo é sobrescrito e perdido.
- Quando usar: É muito raro hoje em dia. Geralmente usado em casos muito específicos de vendas, como quando um representante muda de território e você quer ver os resultados dele tanto na “Região Atual” quanto na “Região Anterior” em uma mesma linha do relatório.
Exemplo Prático:
A vendedora “Mariana” cobria a região “Sul”, mas foi transferida para a região “Sudeste”.
Tabela Antes:
| ID_Vendedor | Nome | Regiao_Atual | Regiao_Anterior |
| 77 | Mariana | Sul | NULL |
Tabela Depois (SCD 3 aplicado):
| ID_Vendedor | Nome | Regiao_Atual | Regiao_Anterior |
| 77 | Mariana | Sudeste | Sul |
Quadro Resumo para Decisão de Arquitetura
Para resumir as diferenças de forma prática na hora de desenhar a modelagem do seu Data Warehouse:
| Característica | SCD Tipo 1 (Sobrescrever) | SCD Tipo 2 (Nova Linha) | SCD Tipo 3 (Nova Coluna) |
| Mantém Histórico? | Não. | Sim, histórico completo. | Sim, mas apenas o último valor. |
| Crescimento da Tabela | Nenhuma linha nova é adicionada. | A tabela cresce verticalmente (novas linhas). | A tabela cresce horizontalmente (novas colunas). |
| Complexidade de Engenharia | Muito baixa. Um simples UPDATE. | Alta. Exige chaves artificiais e controle rigoroso de datas. | Média. Exige alteração na estrutura (DDL) do banco. |
| Cenário Ideal | Correção de erros ortográficos ou dados irrelevantes (ex: hobby do cliente). | Rastreamento oficial de negócio (ex: Endereço para faturamento, cargo atual). | Comparação simples “antes x depois” (ex: Reestruturação de território de vendas). |
O Fluxo Lógico (A Engenharia por trás)
Para aplicar o SCD Tipo 2, o seu pipeline de dados não pode simplesmente “sobrescrever” a tabela. Ele precisa realizar uma operação de Upsert (Update + Insert) complexa seguindo estes passos:
- Comparação: O pipeline lê os dados que acabaram de chegar da fonte e compara com o que já está no seu Data Warehouse.
- Identificação de Mudança: Para saber se algo mudou sem comparar coluna por coluna, os engenheiros costumam usar uma Hash Diff (uma assinatura digital da linha). Se o Hash da fonte for diferente do Hash do destino, algo mudou.
- Fechamento do Passado: O script executa um
UPDATEna linha antiga do banco de dados, preenchendo adata_fimcom o horário atual e alterando o status paraInativo. - Abertura do Futuro: O script executa um
INSERTde uma nova linha com os dados atualizados,data_iniciocomo agora edata_fimcomo nula (ou uma data infinita como 9999-12-31).
Ferramentas Práticas
Usando dbt (Snapshots)
O dbt é a ferramenta favorita para isso hoje. Ele tem uma funcionalidade nativa chamada snapshots. Você apenas define qual é a chave única e qual coluna indica a atualização, e o dbt gera toda a lógica de datas e versões automaticamente para você.
Usando SQL Puro (Merge)
Em bancos como Snowflake, BigQuery ou Databricks, usamos o comando MERGE. É um comando poderoso que consegue inserir ou atualizar registros em uma única transação, garantindo que o histórico não seja corrompido se o processo cair no meio.
3. Exemplo de Código SQL
Imagine que você está atualizando a dimensão de Produtos porque o preço ou a categoria mudaram:
-- Exemplo simplificado de lógica de aplicação SCD 2
-- 1. Marcar como expirado o que mudou
UPDATE dim_produtos
SET data_fim = CURRENT_DATE,
atual = FALSE
WHERE id_produto IN (SELECT id_produto FROM staging_produtos)
AND atual = TRUE;
-- 2. Inserir a nova versão "fresca"
INSERT INTO dim_produtos (sk_produto, id_produto, nome, preco, data_inicio, atual)
SELECT
nextval('seq_sk_produtos'), -- Gera uma nova Surrogate Key
id_produto,
nome,
preco,
CURRENT_DATE,
TRUE
FROM staging_produtos;
O impacto no BI (O consumo do dado)
Para o analista que usa o Power BI ou Tableau, a aplicação prática do SCD Tipo 2 resolve o problema da Integridade Referencial Histórica.
- Sem SCD: Se um produto custava 10 e mudou para 20, todos os gráficos de lucro do ano passado seriam recalculados com o preço de 20, gerando números falsos.
- Com SCD: A tabela Fato de Vendas aponta para a
Surrogate Key(SK) que era válida naquele dia. Assim, a venda de ontem usa a SK do preço 10, e a venda de hoje usa a SK do preço 20. O passado permanece intacto.
Na prática, aplicar SCD é gerenciar Surrogate Keys. Se você tentar fazer histórico usando apenas o ID original do sistema (Natural Key), você vai falhar, pois o ID 42 não pode aparecer duas vezes na mesma tabela como chave primária. A Surrogate Key (1001, 1002…) é o que permite que o ID 42 tenha várias vidas.
