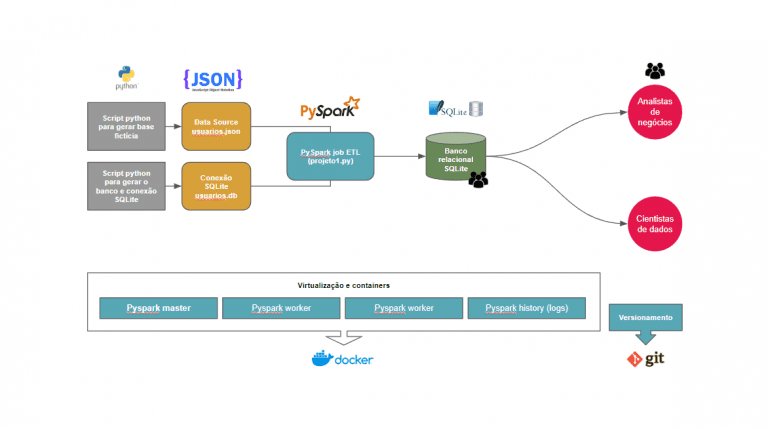
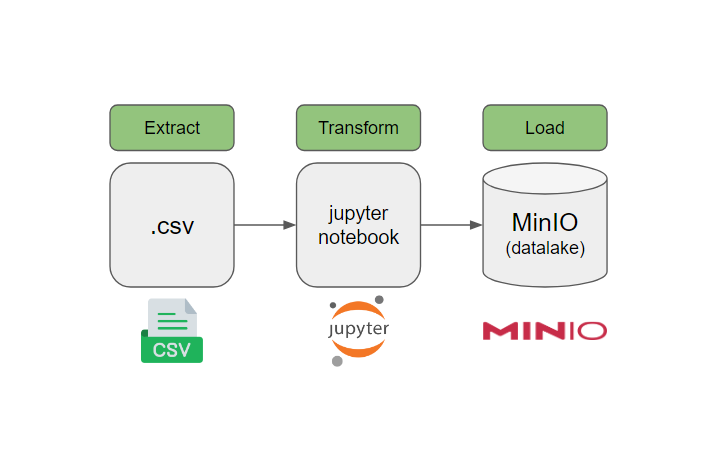
Detalhes do projeto
- Link do projeto no Github: https://github.com/cerqueiralex/etl-com-minio/
- Tecnologias: Python, MinIO
- Categorias: Data Engineering, ETL
MinIO é um armazenamento de objetos de alto desempenho compatível com S3. Ele é projetado para cargas de trabalho de inteligência artificial/aprendizado de máquina em grande escala, data lakes e bancos de dados. É definido por software e pode ser executado em qualquer infraestrutura em nuvem ou local.
Aqui irei organizar os arquivos na nuvem utilizando MiniO em máquina local, que possui os mesmos princípios do serviço S3 da Amazon AWS.
Site oficial: https://min.io
Vantagens e desvantagens de utilizar MinIO como datalake
Vantagens
- Muito bom na recuperação de objetos.
- Boa interface de navegação
- Compatibilidade com formatos diferentes de storage
- Muito fácil criar e trabalhar com buckets a nível de S3
Desvantagens
- Baixa documentação
- Pequenos bugs entre as atualizações
- Dificudade de ver os logs
- Pouco seguro se não for bem implementado
Acessando o Dashboard MinIO utilizando o Docker Localmente
Não irei entrar no detalhe de como subir os containers docker aqui, porém através desta documentação você consegue implantar um servidor MinIO de um único nó e uma única unidade no Docker ou Podman para desenvolvimento inicial e avaliação do Armazenamento de Objetos MinIO e sua camada de API compatível com S3.
Para instruções sobre implantação em ambientes de produção, consulte “Implantação MinIO: Múltiplos Nós, Múltiplas Unidades“.
O MinIO está configurado na URL: http://127.0.0.1:9001 (ele será carregado automaticamente no browser quando o docker estiver up)
Configurando a região
Primeiro é necessário configurar a região do nosso servidor em settings > region. Aqui estarei utilizando a região sa-east-1 (south america) para fazer o processamento dos dados.

Raw Policy e Access Keys
Para poder fazer o ETL, o arquivo python (que pode estar rodando localmente na máquina) precisa se conectar com o banco do MinIO que pode estar localizado em qualquer servidor em qualquer lugar do mundo.
Para isso, é necessário gerar as access keys e para isso, é necessário criar a raw policy primeiro.

Aqui gerei uma política de acesso completa de leitura e escrita, dessa forma posso gravar arquivos, sobrescrevê-los e fazer a leitura deles.

Esse é o formato da raw policy gerada:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::*"
]
}
]
}Gerando as Access Keys
Na área de access keys, gero uma chave para que eu possa conectar o ETL com este servidor Minio.


Assim como na AWS, ao gerar uma chave, você só pode visualizar a Secret key uma única vez, dessa forma é imperativo baixar o arquivo csv que possui a seguinte estrutura contendo as duas chaves:
{"url":"http://127.0.0.1:9000","accessKey":"mnzf2Dw34eOEohXh","secretKey":"kXuPY6NVaHMySNct8INu1LB0lwNVLfYJ","api":"s3v4","path":"auto"}
Por fim, é necessário ir até a access key que acabou de ser criada e aplicar a política de acesso nela, ou seja, estou atribuindo aquelas permissões à uma determinada chave, então quem tiver essa chave, terá permissões de leitura e escrita de arquivos no datalake.
Extraindo os dados e conectando ao MinIO
Beleza, agora que já tenho o ambiente e as chaves configuradas, basta criar um arquivo em python bem simples e conectá-lo ao nosso ambiente.
Para esse exemplo vou utilizar o pandaspara fazer a leitura dos arquivos e transformá-los em dataframes, e o boto3 que é uma biblioteca utilizada para fazer a conexão do cliente com o datalake.
Além disso, importo a classe BytesIO do módulo io em Python.
io é um módulo em Python que fornece várias ferramentas para trabalhar com entrada/saída de dados (I/O). O nome “io” é uma abreviação de “input/output”.
BytesIO é uma classe específica dentro do módulo io. Ela fornece uma interface para ler e escrever dados binários em memória, mas trata esses dados como se fossem provenientes de um fluxo de bytes, sem a necessidade de um arquivo físico.
A utilização típica do BytesIO é criar um objeto BytesIO, escrever dados binários nele e, em seguida, usá-lo onde seria esperado um objeto de arquivo (como, por exemplo, ao ler um arquivo binário).
!pip install pandas
!pip install boto3import pandas as pd
from io import BytesIO
import boto3
from io import StringIO Crio o cliente para conectar ao MinIO. Onde tenho [ACCESS KEY ID] e [SECRET ACCESS KEY] é preciso substituir pelas suas próprias chaves de acesso.
client = boto3.client('s3',
endpoint_url='http://seu-endpoint-aqui:9000',
aws_access_key_id='[ACCESS KEY ID]',
aws_secret_access_key='[SECRET ACCESS KEY]',
aws_session_token=None,
config=boto3.session.Config(signature_version='s3v4'),
verify=False,
region_name='sa-east-1'
)Aqui simplesmente carrego os dados com pandas. Estou utilizando uma base do kaggle “Most Subscribed 1000 Youtube Channels”
https://www.kaggle.com/datasets/themrityunjaypathak/most-subscribed-1000-youtube-channels
# Carregando os dados
file_path = 'topyoutube.csv'
df = pd.read_csv(file_path)
file_pathAntes de fazer o upload do csv, preciso criá-lo e subir o csv na memória
csv_buffer = StringIO ()
df.to_csv(csv_buffer)Escrita: carregando os objetos
Depois que o csv estiver na memória através da função csv_buffer, posso uploadear ele para o datalake. Lembrando que é preciso substituir o “nome-do-bucket” pelo nome correto do seu bucket.
client.put_object (Body=csv_buffer.getvalue(), Bucket='nome-do-bucket', Key="diretorio/dataset.csv")Pronto! agora é possivel verificar o seu objeto no diretorio que foi criado dentro do bucket.

Leitura: visualizando o objeto armazenado
Agora vou fazer o processo inverso -> agora que o arquivo está no datalake, vou ler o arquivo. Para isso é necessário configurar um client de leitura.
obj = client.get_object(
Bucket = 'nome-do-bucket',
Key = "diretorio/dataset.csv"
).get("Body")
data = pd.read_csv(obj)
data.head()