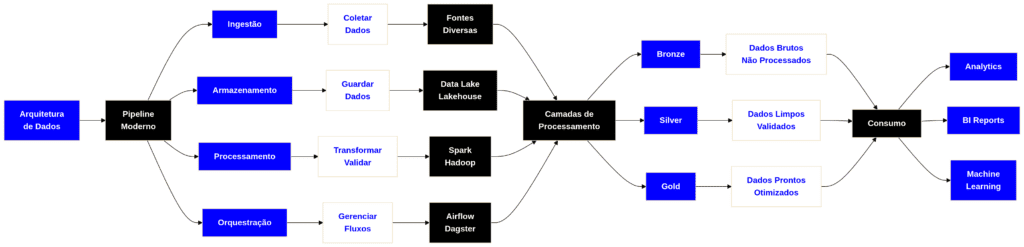
A arquitetura de dados moderna, é dividida logicamente em camadas distintas focadas em preparar, transformar e tornar os dados acessíveis. Essa estrutura garante a confiabilidade, escalabilidade e democratização dos dados em toda a organização.
As duas camadas centrais para este processo são a Camada de Processamento e a Camada de Consumo, que atuam como o motor para transformar informações brutas em insights acionáveis.
A Camada de Processamento: O Motor de Transformação de Dados
A Camada de Processamento é o intermediário vital entre o armazenamento de dados brutos (tipicamente um Data Lake baseado em Amazon S3 e/ou um Data Warehouse como o Amazon Redshift) e os usuários ou sistemas finais.
Seu objetivo é empregar componentes especializados e criados especificamente para lidar efetivamente com as diversas características dos dados modernos, incluindo tipos de dados variados, velocidades extremas (velocidade de chegada) e requisitos complexos de transformação.
Princípios Chave de Design e Interações:
Componentes Criados para Fins Específicos (Purpose-Built Components): Esta camada não é monolítica. Ela utiliza serviços específicos, cada um otimizado para uma carga de trabalho de dados particular (ex: streaming, lote (batch), consultas SQL).
Integração Escalável com o Armazenamento: Todo componente na camada de processamento é projetado para interagir de forma contínua e em escala com a camada de armazenamento fundamental (Amazon S3 e Amazon Redshift). Esse desacoplamento da computação (processamento) do armazenamento é uma marca registrada da arquitetura de nuvem moderna, permitindo o dimensionamento independente.
O Ciclo de Vida da Transformação: O processamento de dados segue um padrão consistente:
- Leitura: Os dados são ingeridos da camada de armazenamento (dados de origem).
- Processamento: Transformações, limpeza, enriquecimento e agregação são aplicadas. Armazenamento temporário (ex: armazenamento local em um cluster Amazon EMR ou áreas de staging temporárias no S3) pode ser usado durante esta fase.
- Escrita: Os resultados processados, refinados e agregados (frequentemente referidos como ‘dados curados’) são gravados de volta em um local designado dentro da camada de armazenamento, prontos para consumo.
Categorias e Casos de Uso Detalhados de Transformação:
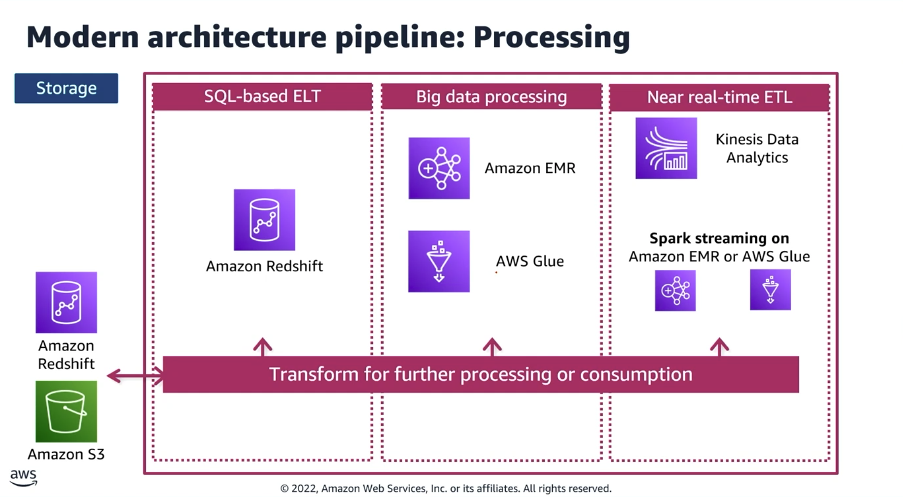
As transformações dentro desta camada são fundamentalmente categorizadas pelo modelo de computação e pelas restrições de latência exigidos:
| Categoria | Método Típico | Tecnologias Primárias | Descrição e Caso de Uso |
| Processamento Baseado em SQL (ELT) | Extract, Load, Transform (ELT) | Amazon Redshift | Ideal para dados estruturados e modelagem dimensional complexa. Os dados são carregados diretamente no data warehouse, e as transformações são executadas usando consultas SQL altamente otimizadas dentro do ambiente do data warehouse. É o preferido para business intelligence e relatórios tradicionais. |
| Processamento de Big Data (ETL) | Extract, Transform, Load (ETL) | Amazon EMR (Hadoop/Spark), AWS Glue | Usado para conjuntos de dados massivos e heterogêneos (estruturados, semi-estruturados e não estruturados). Essas estruturas oferecem computação distribuída e escalável para transformações complexas, limpeza de dados, evolução de schema e integração de diversas fontes. Mais adequado para o processamento de data lake. |
| Processamento Quase em Tempo Real (ETL) | ETL de Streaming | Amazon Kinesis Data Analytics, Spark Streaming no Amazon EMR, AWS Glue Streaming | Lida com feeds de dados de alta velocidade (ex: dados de IoT, clickstreams). As transformações são executadas continuamente em fluxos de dados com latência de sub-segundo ou quase-segundo, permitindo alertas imediatos, dashboards ao vivo e tomada de decisões imediata baseada em eventos atuais. |
Em resumo, a camada de processamento fornece as ferramentas computacionais otimizadas necessárias para preparar e estruturar os dados, tornando-os adequados e confiáveis para a camada de consumo.
A Camada de Consumo: Acesso a Dados e Geração de Insights
A Camada de Consumo representa a fase final do pipeline de dados, alinhando-se com as fases de Análise e Visualização. Ela é projetada para ser o único ponto de acesso unificado para todos os dados e metadados curados que residem na camada de armazenamento.
Sua função principal é democratizar o acesso aos dados, garantindo que cada função de usuário (de analista de negócios a cientista de dados) tenha as ferramentas apropriadas e escaláveis para derivar valor.
Características Chave e Suporte Arquitetural:
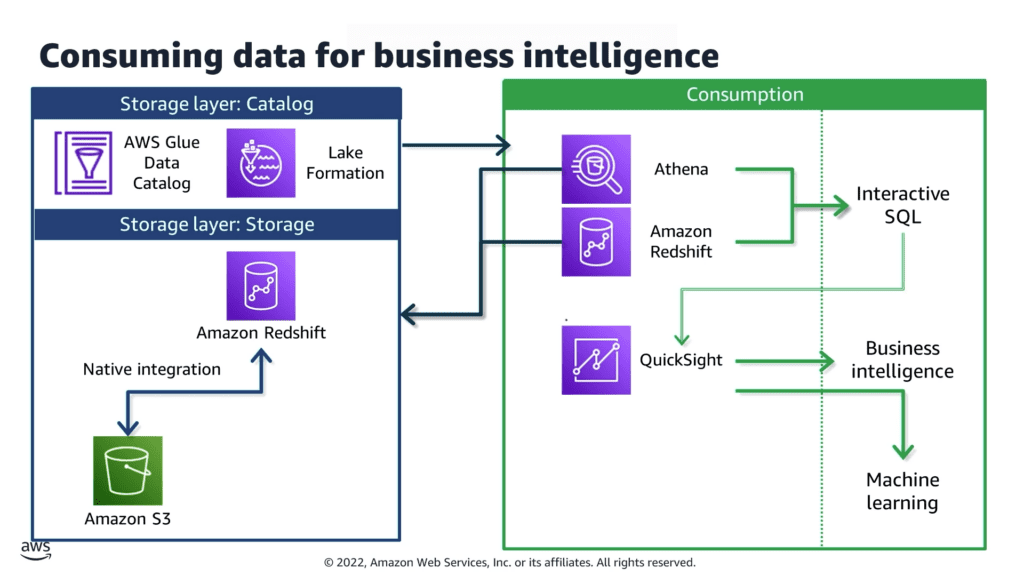
- Acesso Unificado: Esta camada garante que a análise não seja restringida por onde os dados estão localizados. Ela fornece os mecanismos para acessar perfeitamente dados combinados tanto do data warehouse estruturado (suportando schemas tradicionais) quanto do data lake flexível (utilizando formatos abertos como Parquet, ORC e JSON).
- Componentes Escaláveis: As ferramentas dentro desta camada são serverless (sem servidor) ou altamente escaláveis, projetadas para lidar com um grande número de usuários concorrentes e consultas analíticas que exigem muitos recursos, sem degradação de desempenho.
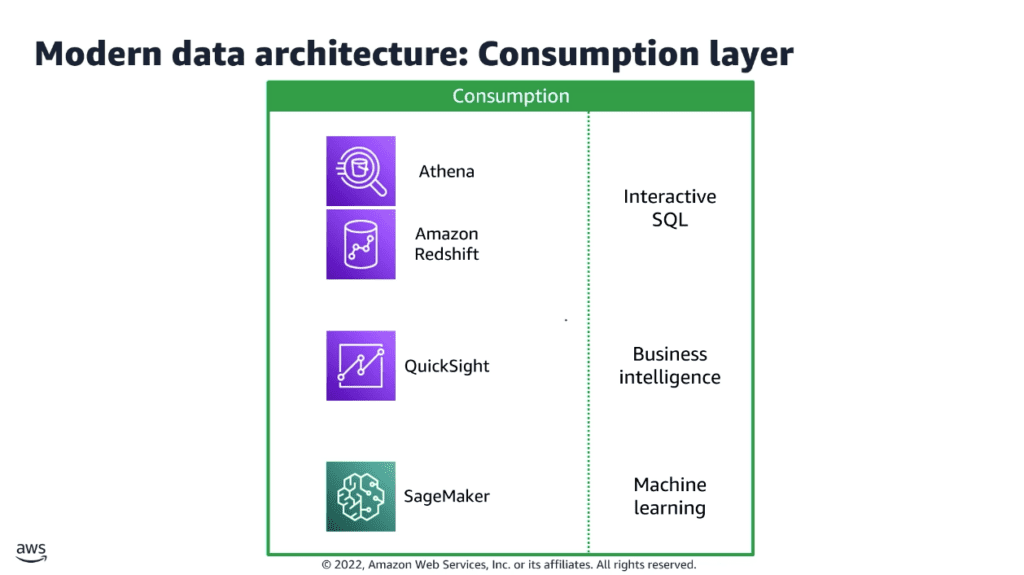
Métodos de Análise Central Suportados:
A arquitetura suporta explicitamente um conjunto diversificado de fluxos de trabalho analíticos, atendendo a diferentes personas e necessidades do usuário:
Consultas SQL Interativas (Análise de Autoatendimento):
- Persona do Usuário: Analistas de Negócios, Cientistas de Dados e Usuários Avançados.
- Função: Permite análise exploratória de dados (AED) e relatórios ad-hoc. Os usuários podem consultar todos os dados, independentemente da escala, usando SQL padrão.
- Tecnologias: Amazon Redshift com Redshift Spectrum (permitindo que o Redshift consulte dados diretamente no S3) e Amazon Athena (um serviço de consulta serverless para dados do S3).
Dashboards de BI (Relatórios Operacionais e Estratégicos):
- Persona do Usuário: Executivos, Gerentes Operacionais e Equipes de Negócios.
- Função: Criação, publicação e distribuição de relatórios e dashboards de business intelligence interativos para monitorar indicadores-chave de desempenho (KPIs) e métricas operacionais.
- Tecnologias: Amazon QuickSight (um serviço de BI serverless). O QuickSight pode ser alimentado por conexões de alto desempenho tanto com o Amazon Athena quanto com o Amazon Redshift. Um valor agregado significativo é a integração do QuickSight de insights de ML gerados automaticamente, como previsão precisa, detecção de anomalias e recursos de consulta em linguagem natural.
Machine Learning (Análise Avançada):
- Persona do Usuário: Cientistas de Dados e Engenheiros de ML.
- Função: O ciclo de vida completo de ML, incluindo preparação de dados, engenharia de features, desenvolvimento de modelo, treinamento e implantação. A arquitetura garante que as ferramentas de ML possam acessar facilmente grandes volumes de dados estruturados e não estruturados.
- Tecnologias: Amazon SageMaker (um serviço de ML totalmente gerenciado) se conecta diretamente aos dados curados na camada de armazenamento (S3 e Redshift) por meio de interfaces simplificadas, abstraindo a complexa “canalização” de dados (data plumbing) e permitindo que os cientistas de dados se concentrem puramente na inovação do modelo.
Resumo das Funções Arquiteturais
| Camada | Função Primária | Cargas de Trabalho/Tipos de Dados Suportados | Principais Resultados |
| Camada de Processamento | Transformar e Curar Dados | ELT baseado em SQL (Redshift), ETL de Big Data (EMR/Glue), ETL Quase em Tempo Real (Kinesis/Streaming) | Dados limpos, validados, agregados e prontos para consumo na camada de armazenamento. |
| Camada de Consumo | Acesso a Dados e Geração de Insights | Consultas SQL Interativas, Dashboards de BI, Machine Learning | Democratização de Dados, Análise Ad-Hoc, Relatórios Operacionais e Modelagem Preditiva. |
