A estrutura fundamental de um pipeline analítico focado nas camadas de ingestão e armazenamento baseia-se na divisão do ecossistema em ferramentas específicas de ingestão, as quais se integram diretamente a um repositório durável e escalável. Paralelamente, ocorre a integração de um catálogo de metadados para garantir a governança e a descoberta dos ativos corporativos.
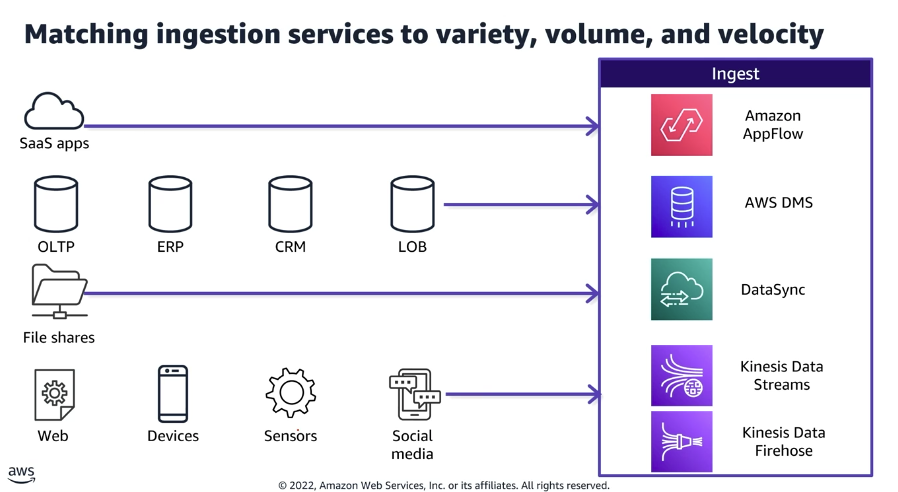
1. Camada de Ingestão: Alinhamento por Volume, Variedade e Velocidade
A seleção das ferramentas de ingestão é realizada com base nas características intrínsecas da fonte geradora. Essa adequação tecnológica evita gargalos de I/O e garante a latência esperada para o negócio. A estruturação dos pipelines de ingestão respeita a seguinte correspondência de serviços:
| Categoria da Fonte de Dados | Exemplos de Origem | Serviço de Ingestão AWS Recomendado |
| Aplicações de Terceiros | SaaS apps | Amazon AppFlow |
| Sistemas Relacionais e Negócio | OLTP, ERP, CRM, LOB | AWS DMS (Database Migration Service) |
| Sistemas de Arquivos | File shares | AWS DataSync |
| Streaming e Eventos em Tempo Real | Web, Dispositivos Móveis, Sensores (IoT), Mídias Sociais | Amazon Kinesis Data Streams e Kinesis Data Firehose |

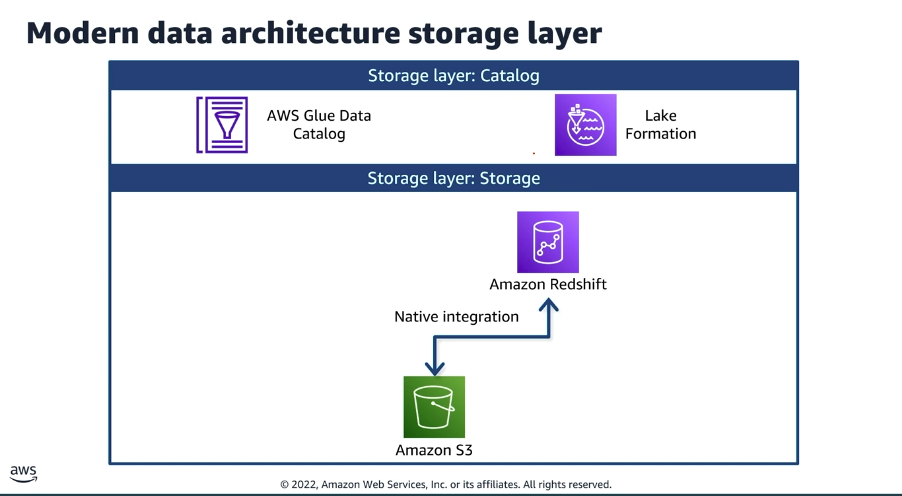
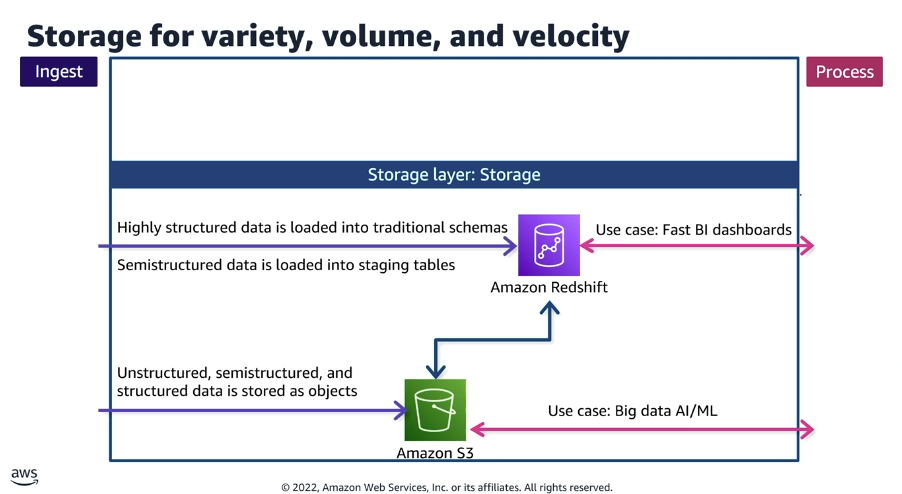
A alocação dos dados obedece à sua estrutura e ao caso de uso analítico final. A arquitetura moderna utiliza o Amazon S3 como fundação do Data Lake e o Amazon Redshift como motor de Data Warehouse, mantendo uma integração nativa e bidirecional entre eles.
- Armazenamento de Big Data (Data Lake): Dados não estruturados, semiestruturados e estruturados são depositados na forma de objetos dentro do Amazon S3. Este repositório é desenhado para suportar cargas de trabalho massivas de Inteligência Artificial e Machine Learning (AI/ML).
- Armazenamento Analítico Estruturado (Data Warehouse): Informações altamente estruturadas são carregadas em esquemas tradicionais no Amazon Redshift. Este fluxo é direcionado estritamente para alimentar dashboards de Business Intelligence (BI) que exigem alta velocidade e baixa latência. Quando necessário, a movimentação de dados semiestruturados do S3 para o Redshift ocorre utilizando tabelas intermediárias (staging tables).
3. Zonas de Armazenamento: Estruturação de Estados de Dados
A organização do Data Lake no Amazon S3 utiliza prefixos lógicos ou buckets individuais para representar as diferentes zonas e o estado de maturidade da informação. O fluxo de refinamento contínuo é estabelecido nas seguintes etapas:
- Landing: O dado é recebido e acomodado em seu formato original, oriundo diretamente das ferramentas de ingestão.
- Raw: Rotinas de limpeza (Clean) são executadas para remover inconsistências sistêmicas graves.
- Trusted: A etapa de estruturação (Structure) e padronização de tipos de dados é aplicada.
- Curated: A informação é enriquecida e validada (Enrich and validate) por meio da aplicação de regras de negócio definitivas.
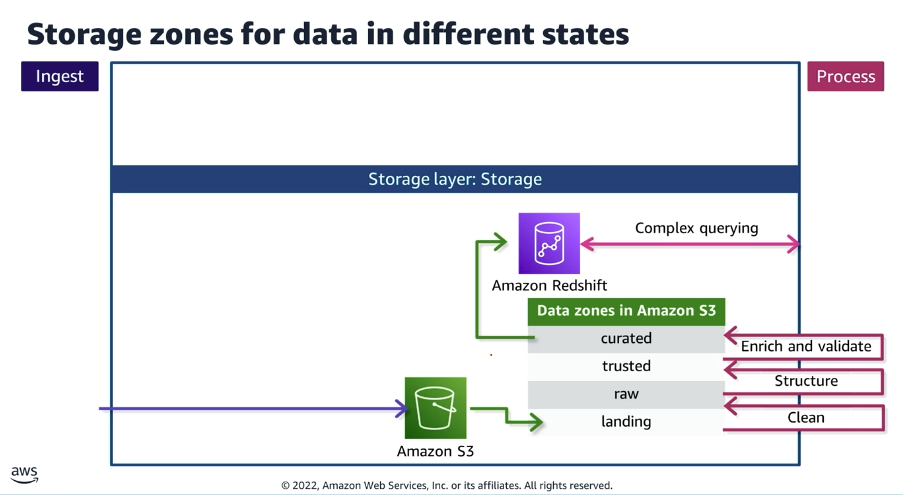
As consultas complexas (complex querying) processadas pelo Amazon Redshift são apontadas diretamente para a zona Curated, onde o dado possui o maior nível de confiabilidade.
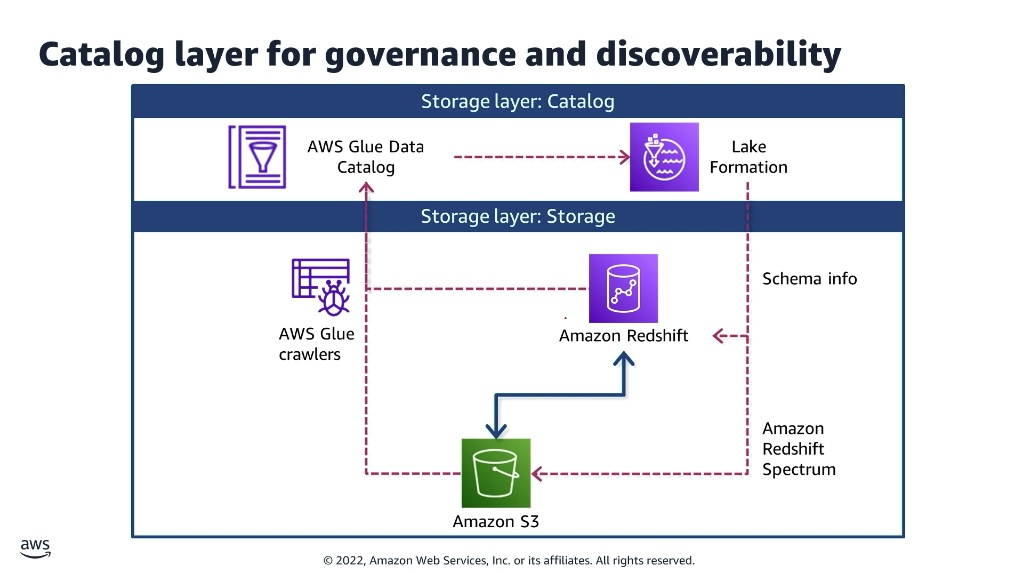
4. Camada de Catálogo: Governança e Interoperabilidade
As instâncias de armazenamento físico são sobrepostas por uma camada lógica de catálogo. Sem esta camada, o ambiente tende a se degenerar com o tempo, perdendo a rastreabilidade estrutural.
- Extração de Metadados: O serviço AWS Glue Crawlers atua contra os buckets do Amazon S3 para rastrear os arquivos, inferir sua estrutura e atualizar automaticamente os esquemas lógicos.
- Centralização de Registros: Os metadados inferidos são centralizados no AWS Glue Data Catalog, enquanto as políticas de acesso a esses dados são governadas através do AWS Lake Formation.
- Consultas Federadas: O mecanismo Amazon Redshift Spectrum entra em ação para ler as informações de esquema diretamente da camada de catálogo. Isso permite que consultas analíticas sejam executadas de forma transparente contra os dados físicos residentes no Amazon S3, o que elimina a necessidade de duplicar ou movimentar os dados de forma redundante para os discos locais do banco de dados analítico.