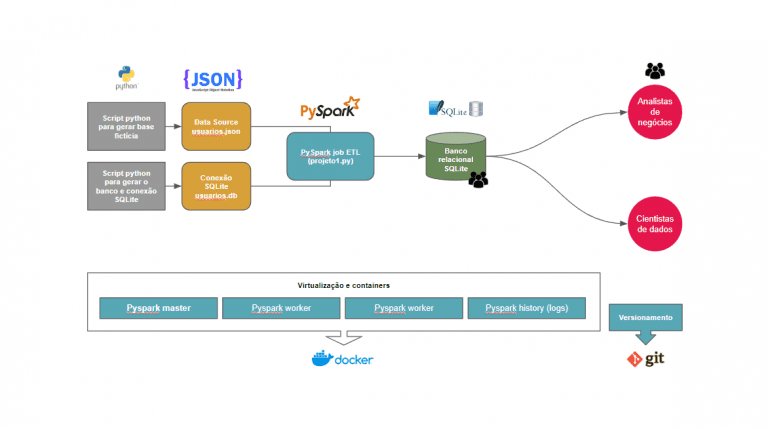
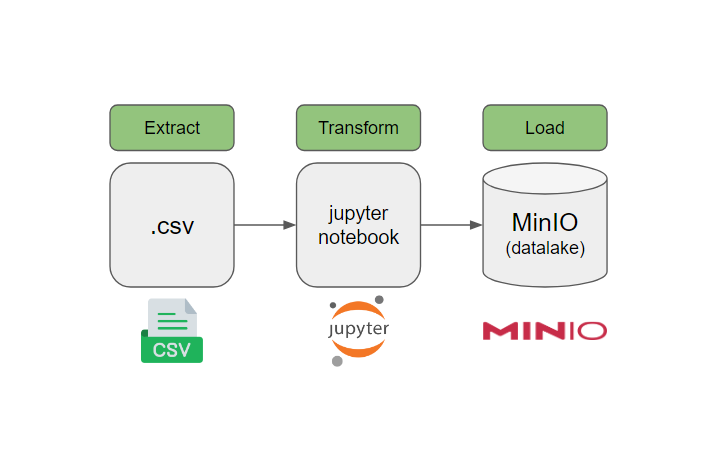
Com o crescimento exponencial do volume e da complexidade dos dados, as empresas buscam soluções mais rápidas, eficientes e econômicas para gerenciar e analisar informações.
Nos últimos anos, os data warehouses baseados em nuvem revolucionaram o processamento de dados ao incorporar arquiteturas de processamento massivamente paralelo (MPP) e suporte avançado a SQL.
Esse avanço permitiu o surgimento de um ecossistema de ferramentas nativas da nuvem que são escaláveis, acessíveis e fáceis de operar.
O Modern Data Stack (MDS) é um conjunto de tecnologias e ferramentas projetadas para coletar, armazenar, processar e analisar dados de maneira escalável, eficiente e com custos otimizados, mas diferente das arquiteturas tradicionais, no caso das stacks modernas, o foco está nos dados, permitindo que as empresas os gerenciem de forma mais estratégica e extraiam valor significativo dessas informações.
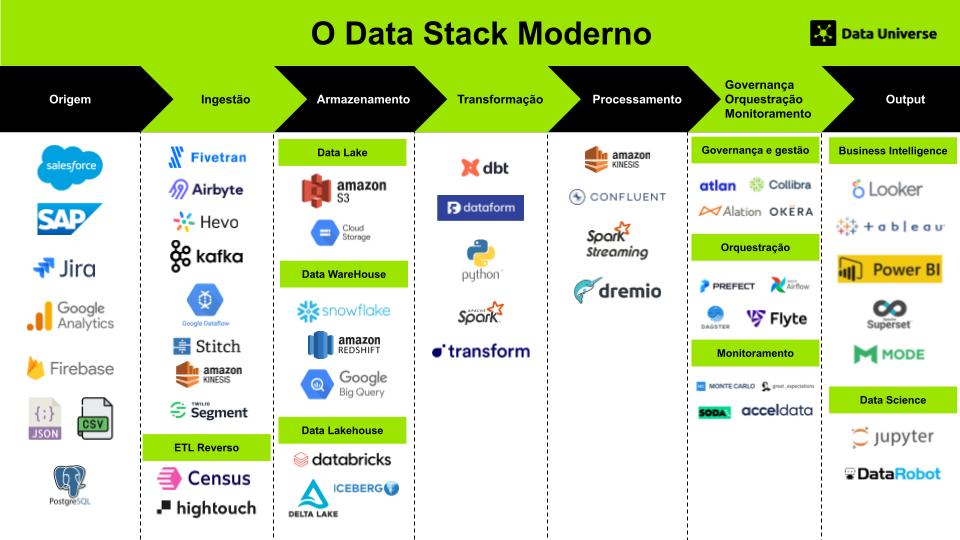
Arquitetura do Modern Data Stack
Para exemplificar, imagine uma empresa do setor de turismo que deseja aprimorar a experiência do cliente por meio de recomendações personalizadas. Para isso, ela precisa coletar, processar e analisar grandes volumes de dados provenientes de múltiplas fontes, como históricos de reservas armazenados em um CRM, registros de buscas capturados pelo Google Analytics e interações em redes sociais.
Com um stack de dados moderno, essa empresa pode otimizar seu fluxo de dados ao utilizar um data warehouse na nuvem, como o Snowflake, ferramentas de integração de dados, como o Stitch, e soluções de visualização, como o Power BI.
Além disso, a escalabilidade de uma stack moderna permite que a empresa aumente sua capacidade de processamento conforme o volume de dados cresce, sem a necessidade de reformular toda a infraestrutura.
Ao transformar esses dados em insights acionáveis, a empresa pode oferecer recomendações mais precisas, melhorar a satisfação dos clientes e impulsionar o crescimento do negócio.
O Marco na Evolução do Modern Data Stack
O grande avanço na stack moderna ocorreu por volta de 2012 com a introdução dos data warehouses baseados em nuvem.
Plataformas como Redshift, BigQuery e Synapse são os principais data warehouses nativos da nuvem, oferecidos pelos três principais provedores de serviços em nuvem: Amazon AWS, Google Cloud Platform (GCP) e Microsoft Azure, respectivamente.
Além desses, o Snowflake também se destaca como uma solução popular de data warehouse, com a flexibilidade de ser hospedada em qualquer uma das três grandes nuvens.
Esses data warehouses trouxeram facilidade no armazenamento e utilização de dados, e sua cobrança baseada no consumo proporcionou uma flexibilidade significativa para adoção e escalabilidade.
O Crescimento do Mercado de Software de Gerenciamento de Dados
O mercado global de software de gerenciamento de dados superou a marca de $70 bilhões em 2021, e as projeções apontam para um crescimento para $150 bilhões até 2027.
Esse aumento no interesse pela stack moderna nos últimos anos reflete a crescente adoção dessas tecnologias.
A transição das empresas para a tomada de decisões baseadas em dados gerou uma demanda crescente por processamento de dados em tempo real e ferramentas de BI/analytics.
A Influência da IA/ML e IoT na Infraestrutura de Dados
O avanço de IA/ML (Inteligência Artificial e Machine Learning) e IoT (Internet das Coisas) tem sido um dos principais impulsionadores no desenvolvimento da infraestrutura de dados.
A capacidade de gerar e analisar grandes volumes de dados oferece uma vantagem competitiva significativa no mercado, e por isso, cada vez mais empresas buscam se transformar em “empresas de dados”, alavancando suas operações por meio de uma abordagem orientada por dados.
Principais diferenças entre a stack moderna e a estrutura tradicional
A principal diferença é que a Modern Data Stack traz maior agilidade, escalabilidade e menor custo, permitindo que até pequenas empresas tenham acesso a tecnologias avançadas sem a complexidade das infraestruturas tradicionais.
| Aspecto | Stack de Dados Tradicional | Modern Data Stack (MDS) |
|---|---|---|
| Infraestrutura | On-premises (servidores físicos, data centers próprios). | Baseada na nuvem (AWS, GCP, Azure, Snowflake). |
| Escalabilidade | Limitada, exige compra de hardware adicional para crescer. | Elástica e sob demanda, cresce conforme a necessidade. |
| Armazenamento | Data Warehouses tradicionais (Ex: Oracle, Teradata). | Data Warehouses modernos (Snowflake, BigQuery, Redshift) e Data Lakes (Databricks, Delta Lake). |
| Processamento de Dados | ETL (Extract, Transform, Load) com processos pesados antes da carga. | ELT (Extract, Load, Transform), permitindo transformação pós-ingestão na nuvem. |
| Tempo de Processamento | Lento e batch (execução em horários programados). | Rápido e muitas vezes em tempo real (streaming com Kafka, Kinesis). |
| Orquestração | Ferramentas complexas e customizadas (ETL scripts). | Soluções modulares e low-code/no-code (Apache Airflow, Dagster, Prefect). |
| Integração de Dados | Demorada e cara, exige pipelines manuais e manutenção constante. | Ferramentas automatizadas (Fivetran, Airbyte, Stitch) reduzem o esforço. |
| Qualidade e Governança | Monitoramento manual, pouca observabilidade. | Ferramentas automatizadas (Monte Carlo, Great Expectations, Datafold). |
| Análise e BI | Relatórios demorados, ferramentas tradicionais (Excel, SAP BO). | Dashboards ágeis e interativos (Looker, Tableau, Metabase, Power BI). |
| Custo | Alto custo inicial e manutenção contínua de servidores. | Modelo pay-as-you-go, mais acessível para empresas de todos os portes. |
| Time Responsável | Equipes grandes e especializadas em infraestrutura e ETL. | Equipes menores, focadas em análise e engenharia de dados. |
Os data stacks tradicionais geralmente são soluções on-premises, baseadas em uma infraestrutura de hardware e software gerenciada internamente pela própria organização.
Construídos sobre arquiteturas monolíticas, esses sistemas exigem investimentos significativos tanto em infraestrutura de TI quanto em pessoal especializado. Além disso, sua integração com ambientes cloud-based costuma ser limitada, tornando-os menos flexíveis e escaláveis quando comparados às soluções modernas.
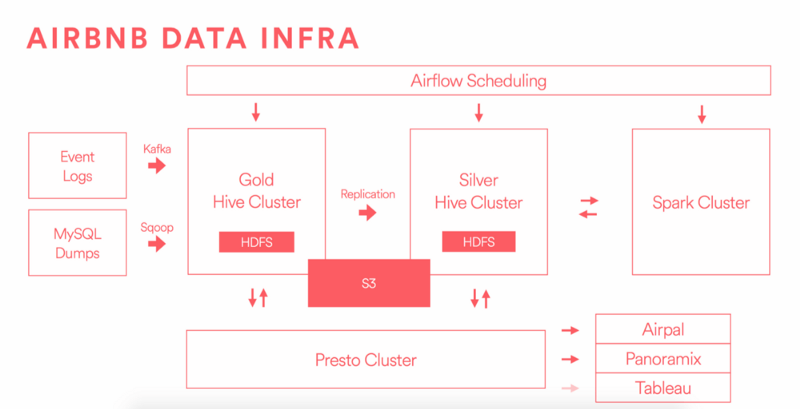
Exemplos de arquiteturas modernas: Airbnb
O Airbnb é um excelente exemplo de como o Modern Data Stack pode ser aplicado para lidar com grandes volumes de dados e fornecer recomendações personalizadas aos usuários. Com mais de 100 milhões de usuários e um catálogo de mais de 2 milhões de anúncios, a plataforma precisa de um sistema de dados altamente escalável e eficiente para sugerir destinos relevantes e aprimorar a experiência do usuário.
Infraestrutura de Dados do Airbnb
O time de engenharia de dados do Airbnb compartilha insights técnicos no blog AirbnbEng, onde discutem suas estratégias para gerenciar dados em larga escala.
Um dos destaques é sua arquitetura de dados moderna, que permite integrar diversas fontes de informação, realizar análises avançadas e alimentar modelos de machine learning para personalização de recomendações.
Investimento em Equipe de Dados
Durante um evento chamado “Building a World-Class Analytics Team“, Elena Grewal, Gerente de Ciência de Dados do Airbnb, revelou que a empresa já contava com mais de 30 engenheiros de dados.
Esse número representa um investimento significativo, estimado em mais de 5 milhões de dólares anuais apenas em salários, refletindo a importância estratégica que a empresa dá à sua infraestrutura de dados.
O caso do Airbnb ilustra como empresas inovadoras estão apostando no Modern Data Stack para escalar suas operações, melhorar a experiência do usuário e impulsionar o crescimento do negócio por meio de decisões baseadas em dados.
Principais motivações para a evolução da arquitetura
1. Ingestão de Dados
| Tradicionalmente | Na abordagem moderna |
|---|---|
| A ingestão de dados era feita em lotes (batch processing), onde sistemas ETL (Extract, Transform, Load) coletavam dados de diferentes fontes e os carregavam periodicamente em um data warehouse. Ferramentas como Informatica PowerCenter e Talend eram comuns. | Com o crescimento exponencial dos dados e a necessidade de análises em tempo real, o modelo de event-driven ingestion se tornou mais relevante. Soluções como Apache Kafka e Amazon Kinesis permitem a captura e processamento contínuo de eventos em streaming, garantindo maior agilidade na tomada de decisão. |
Motivo da mudança: O modelo tradicional gerava latência entre a geração e a análise dos dados. No modelo moderno, o consumo em tempo real possibilita reações mais rápidas e insights imediatos.
2. Armazenamento de Dados
| Tradicionalmente | Na abordagem moderna |
|---|---|
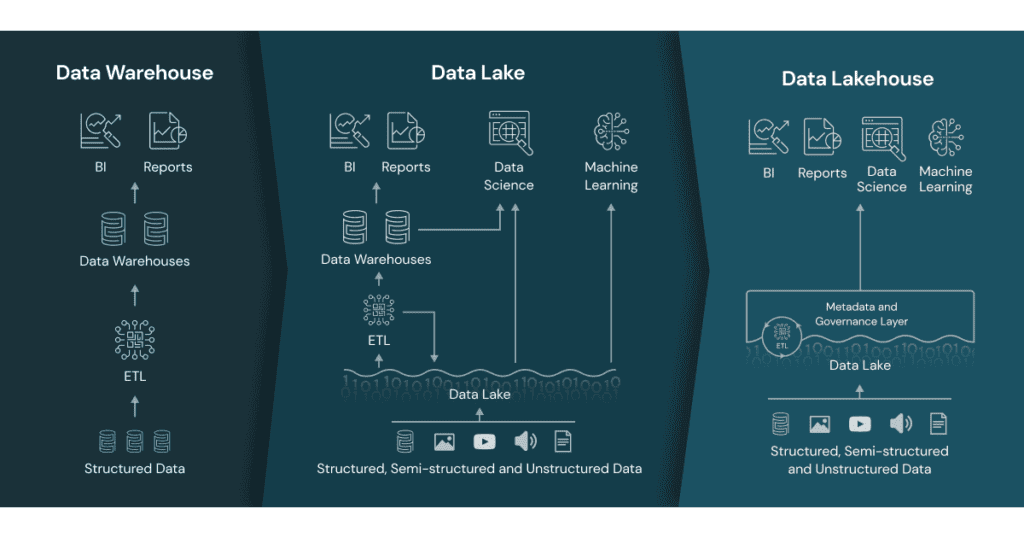
| O armazenamento de dados era feito em data warehouses on-premises, exigindo grande investimento em hardware e manutenção. Sistemas como Oracle Exadata e Teradata eram comuns. | O uso de data warehouses na nuvem (como BigQuery, Snowflake e Redshift) eliminou a necessidade de infraestrutura própria. Além disso, surgiram data lakes (como AWS S3 e Azure Data Lake) para armazenar grandes volumes de dados brutos e não estruturados, e mais recentemente, o data lakehouse (como Databricks) combinou o melhor dos dois mundos. |
Motivo da mudança: A computação em nuvem trouxe elasticidade e redução de custos, permitindo escalabilidade conforme a demanda, sem necessidade de provisionamento excessivo de recursos.
3. Processamento e Transformação de Dados
| Tradicionalmente | Na abordagem moderna |
|---|---|
| Os dados eram transformados antes de serem carregados no data warehouse (ETL), usando ferramentas como Informatica, DataStage e SSIS. O processamento ocorria em máquinas dedicadas, com escalabilidade limitada. | O modelo mudou para ELT (Extract, Load, Transform), onde os dados são primeiro carregados no data warehouse e depois transformados com ferramentas como dbt (data build tool), aproveitando o poder de processamento nativo do banco. Além disso, frameworks distribuídos como Apache Spark processam grandes volumes de dados de forma paralela e escalável. |
Motivo da mudança: O ELT aproveita a capacidade de processamento dos cloud data warehouses, reduzindo o tempo de carregamento e permitindo maior flexibilidade na modelagem dos dados.
4. Orquestração de Pipelines
| Tradicionalmente | Na abordagem moderna |
|---|---|
| A execução de pipelines era gerenciada por cron jobs e soluções legadas como Control-M e Oozie, exigindo scripts personalizados e pouca automação inteligente. | Ferramentas de orquestração como Apache Airflow, Dagster e Prefect permitem a automação flexível e monitoramento centralizado de workflows, suportando dependências complexas e integrações com múltiplas fontes de dados. |
Motivo da mudança: A necessidade de maior observabilidade, controle e escalabilidade nos processos de dados impulsionou a adoção de orquestradores modernos, que oferecem interface visual, logging avançado e gestão eficiente de falhas.
5. Análise e BI (Business Intelligence)
| Tradicionalmente | Na abordagem moderna |
|---|---|
| Ferramentas como Tableau, MicroStrategy e Power BI processavam os dados armazenados no data warehouse, mas muitas vezes dependiam de extrações demoradas e relatórios pré-agregados. | A análise de dados se tornou mais interativa e self-service, com ferramentas como Looker, Mode Analytics e Metabase integrando-se diretamente ao data warehouse sem necessidade de extrações manuais. Além disso, a BI em tempo real ganhou força com soluções baseadas em streaming analytics. |
Motivo da mudança: As empresas precisam de respostas mais rápidas, e o processamento direto no data warehouse, sem necessidade de pré-processamento, possibilita análises mais dinâmicas e atualizadas.
6. Machine Learning e Inteligência Artificial
| Tradicionalmente | Na abordagem moderna |
|---|---|
| Modelos de Machine Learning eram treinados separadamente em servidores locais, exigindo pipelines customizadas e integrações complexas. | Plataformas como Databricks ML, Vertex AI (Google Cloud) e AWS SageMaker oferecem ambientes escaláveis para treinamento e deploy de modelos diretamente na nuvem, facilitando a operacionalização de MLOps. |
Motivo da mudança: A necessidade de escalabilidade, automação e integração direta com a infraestrutura de dados levou à adoção de plataformas especializadas que simplificam o ciclo de vida dos modelos de IA/ML.
Principais Características da Stack Moderna
Seis características fundamentais definem e destacam o Modern Data Stack em relação às infraestruturas tradicionais:
1. Cloud-First
Nativamente baseado na nuvem, o que permite escalabilidade elástica, maior flexibilidade e integração simplificada com infraestruturas cloud já existentes.
2. Construído em torno de data warehouses, data lakes ou data lakehouses
As ferramentas modernas de dados são projetadas para integração direta com data warehouses na nuvem como Redshift, BigQuery e Snowflake, além de data lakes e data lakehouses (um híbrido entre os dois primeiros).
3. Arquitetura Modular
Diferente dos data stacks tradicionais, onde a substituição de um único componente pode ser complexa e arriscada, a stack moderna adota uma abordagem modular. Isso significa que:
- Componentes podem ser substituídos sem comprometer todo o sistema.
- Organizações podem escolher ferramentas específicas conforme suas necessidades.
- Evita o vendor lock-in, dando maior controle sobre a infraestrutura de dados.
4. Forte Apoio da Comunidade Open-Source
Muitos dos componentes da stack moderna são open-source, como Apache Airflow, Kafka, Spark, entre outros. Isso cria um ecossistema colaborativo de usuários e desenvolvedores que contribuem para a evolução das ferramentas, organizam eventos e trocam conhecimento em comunidades como Slack, Reddit e meetups especializados.
5. Opções SaaS e Serviços Gerenciados
Embora o software open-source seja altamente vantajoso, muitas ferramentas exigem expertise técnica avançada, pois geralmente não possuem interfaces gráficas intuitivas. Para facilitar a adoção, algumas soluções modernas são oferecidas como serviços SaaS (Software as a Service) ou plataformas low-code/no-code, tornando-as acessíveis para profissionais de dados com pouca experiência em engenharia de dados.
6. Democratização do Acesso a Dados
Diferente dos modelos tradicionais, onde o acesso a dados fica restrito a poucos especialistas, a stack moderna promove a democratização dos dados dentro da organização. Isso significa que:
- Qualquer colaborador pode acessar e consultar dados de forma independente.
- A cultura orientada a dados se fortalece, aumentando a tomada de decisões baseada em insights.
- Elimina gargalos criados pela dependência de poucos analistas especializados.
Pontos positivos e negativos que essa evolução trouxe consigo
O Modern Data Stack trouxe eficiência, escalabilidade e acessibilidade ao mundo dos dados, mas ainda existem desafios críticos a serem resolvidos.
O futuro dependerá da evolução de governança de dados, streaming analytics, integração com ferramentas operacionais e interfaces mais acessíveis para usuários não técnicos em alguns cenários.
| Pontos positivos | Pontos Negativos |
|---|---|
| Produtos Horizontais Antigamente, era necessário adquirir várias ferramentas específicas para analisar diferentes conjuntos de dados. Com o MDS, os dados são centralizados em um data warehouse, permitindo a análise unificada em uma única stack de ferramentas comuns. Velocidade O MDS permite uma conexão rápida com novas fontes de dados e facilita a exploração analítica. A performance dos bancos de dados MPP (Massively Parallel Processing) proporciona alta velocidade de execução de queries, acelerando o processo de tomada de decisão. Escalabilidade Ilimitada Com a infraestrutura em nuvem, é possível escalar o processamento e armazenamento de dados sem limites técnicos significativos. O principal fator limitante passou a ser o custo, e não a capacidade da tecnologia. Baixo Overhead Operacional Em 2012, era necessário um time robusto de engenheiros para gerenciar a infraestrutura de dados. Hoje, o MDS reduz essa necessidade, tornando possível operar pipelines de dados sofisticados sem grandes investimentos em infraestrutura e engenharia. Integração Padronizada via SQL No passado, não havia um padrão claro para integração entre diferentes produtos de dados. Atualmente, SQL é a linguagem comum em todos os componentes do MDS, facilitando a integração e democratizando o acesso aos dados para um público mais amplo. | Governança Imatura: A facilidade de coletar e transformar dados na stack moderna traz riscos de desorganização. Ainda faltam ferramentas e boas práticas para garantir confiança, segurança e contexto nos dados. Arquitetura Baseada em Lotes (Batch Processing) O MDS ainda opera majoritariamente em processamento em lote, utilizando agendamentos e polling para coletar dados. A transição para streaming poderia desbloquear ainda mais valor, permitindo uma análise quase em tempo real. Falta de Integração com Ferramentas Operacionais Atualmente, os dados fluem apenas em uma direção, das fontes para o data warehouse e para dashboards. Para maximizar o impacto, seria essencial integrar os insights diretamente com ferramentas operacionais como CRMs, plataformas de e-commerce e sistemas de mensagens. Acesso Limitado para Consumidores de Dados Apesar da acessibilidade via SQL, muitos consumidores de dados ainda dependem de analistas para realizar consultas. No passado, usuários finais tinham maior autonomia utilizando ferramentas familiares como Excel, algo que ainda não foi completamente resolvido na stack moderna. Perda de Experiências Analíticas Verticais A consolidação dos dados em infraestruturas centralizadas eliminou algumas ferramentas especializadas por domínio. Experiências analíticas otimizadas para áreas como marketing, vendas e mobile analytics são fundamentais para garantir insights mais precisos e contextualizados. |
Como os objetivos e prioridades das empresas mudaram?
A arquitetura evoluiu significativamente devido às mudanças nos objetivos das empresas, que hoje priorizam velocidade, escalabilidade, inteligência artificial e análise em tempo real.
- Década passada (2010-2020) → Empresas focavam em relatórios estáticos, BI tradicional e ETL para armazenar e processar dados estruturados.
- Atualmente (2020-2025) → Empresas querem dados em tempo real, machine learning/IA, personalização em escala e decisões automatizadas.
Esse shift estratégico exigiu mudanças profundas na arquitetura de dados.

A abordagem tradicional, baseada em data warehouses locais e ETL tradicional, não suportava a velocidade e a variedade dos dados necessários para IA e aprendizado de máquina. Com isso, foram adotadas tecnologias baseadas na nuvem, permitindo ingestão contínua de dados via streaming, armazenamento escalável e processamento distribuído.
Isso possibilitou a utilização de arquiteturas híbridas como o conceito de lakehouse, combinando a flexibilidade de data lakes com a estruturação dos data warehouses.
A escalabilidade também se tornou um fator crítico. Antes, as empresas investiam em servidores físicos e infraestrutura pesada, o que limitava a capacidade de crescimento. Hoje, soluções como Snowflake, BigQuery e Databricks permitem que qualquer empresa processe grandes volumes de dados sem precisar gerenciar hardware.
Além disso, a separação entre armazenamento e processamento trouxe mais eficiência ao consumo de recursos, reduzindo custos operacionais e permitindo que empresas paguem apenas pelo que utilizam.
Outro ponto fundamental é a automação e a democratização do acesso aos dados. No passado, equipes de engenharia de dados eram responsáveis por construir pipelines complexos e manter sistemas robustos, o que restringia a velocidade de inovação.
Agora, ferramentas low-code e no-code como Fivetran e dbt reduzem a necessidade de intervenção manual, permitindo que analistas e cientistas de dados foquem na geração de insights e na criação de modelos avançados de IA.
O avanço da inteligência artificial também impulsionou a adoção de novas práticas na governança de dados. Modelos de machine learning dependem da qualidade, diversidade e integridade dos dados, e isso forçou as empresas a investirem mais em soluções de observabilidade e confiabilidade, como Monte Carlo e Great Expectations.
Além disso, frameworks de engenharia de dados modernos tornaram mais fácil versionar, rastrear e auditar pipelines, garantindo que os dados usados para treinar modelos sejam confiáveis e reproduzíveis.
A mudança na arquitetura reflete a necessidade das empresas de serem mais dinâmicas, orientadas por dados e preparadas para a era da inteligência artificial. O foco deixou de ser apenas armazenar e consultar dados de forma eficiente e passou a ser sobre como transformar esses dados em vantagem competitiva, automatizando decisões e personalizando experiências em tempo real.
Referências:
- https://www.getdbt.com/blog/future-of-the-modern-data-stack
- https://keen.io/blog/architecture-of-giants-data-stacks-at-facebook-netflix-airbnb-and-pinterest/
- https://www.altexsoft.com/blog/modern-data-stack/
- https://kae-capital.com/blogs/the-modern-data-stack/
- https://medium.com/@kamini_74876/key-trends-in-modern-data-stack-4dd6f213f7e6