A evolução do processamento de dados exigiu a transição de sistemas monolíticos para ecossistemas distribuídos, modulares e elásticos. Historicamente, pipelines dependiam de processos ETL (Extract, Transform, Load) rígidos, executados em lote (batch) durante a madrugada, alimentando um Data Warehouse centralizado e hospedado em infraestrutura local (on-premise). Esse modelo não suporta o volume, a velocidade e a variedade dos dados gerados atualmente.
Para compreender a necessidade da Modern Data Architecture, analise o seguinte exemplo hipotético:
Uma rede de varejo global precisa recomendar produtos em seu aplicativo em tempo real. No modelo tradicional, a compra do cliente só seria processada no dia seguinte, tornando a recomendação obsoleta.
Com uma arquitetura de dados moderna, o clique do usuário flui através de uma ferramenta de mensageria instantânea (Streaming), cruza com o histórico de compras armazenado em um sistema de armazenamento em nuvem e alimenta um modelo de Machine Learning em segundos.
A recomendação aparece antes de o cliente fechar o aplicativo.
Modern Data Architecture
Sob a perspectiva da engenharia, a Modern Data Architecture (MDA) é um conjunto de princípios estruturais, tecnologias em nuvem e padrões de design de software aplicados à gestão de dados.
Ela é fundamentalmente caracterizada pela separação entre armazenamento e processamento (Decoupled Compute and Storage). Isso significa que os dados repousam em um repositório de baixo custo e alta disponibilidade (como Object Storages), enquanto os motores de processamento são provisionados e escalados sob demanda de forma independente.
Uma arquitetura moderna integra dados estruturados, semiestruturados e não estruturados, combinando a flexibilidade de um Data Lake com o rigor de transações ACID (Atomicidade, Consistência, Isolamento e Durabilidade) e a governança de um Data Warehouse, culminando no paradigma conhecido como Data Lakehouse.
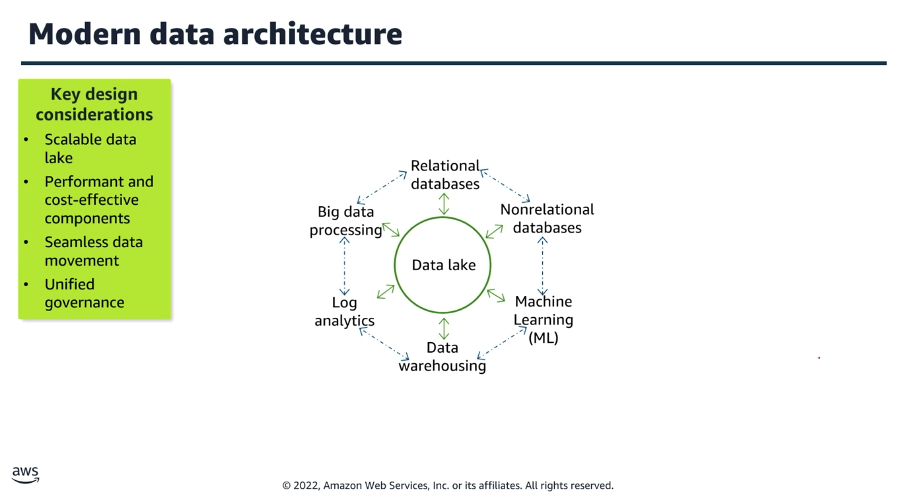
Modern Data Stack
O Modern Data Stack (MDS) é uma definição focada no conjunto de tecnologias e ferramentas projetadas para coletar, armazenar, processar e analisar dados de maneira escalável, eficiente e com custos otimizados.
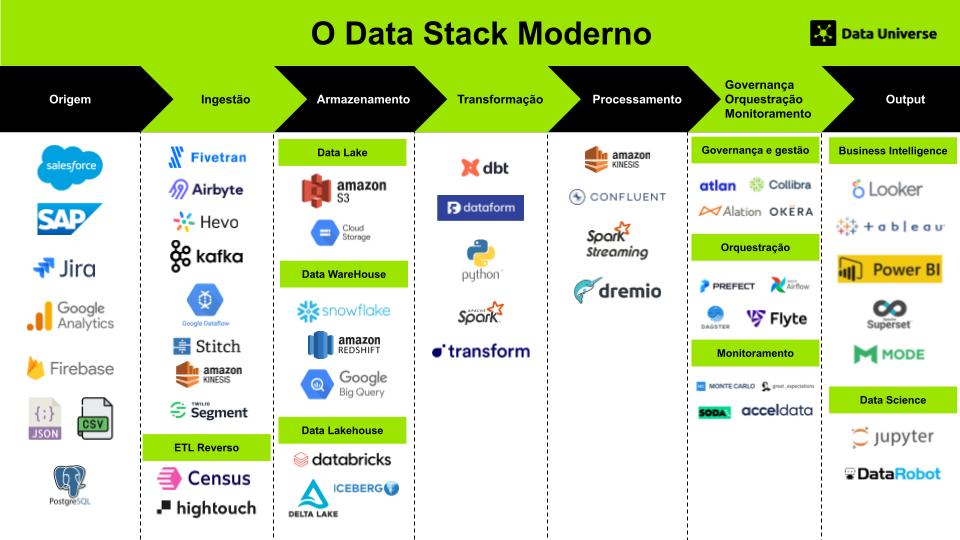
Qual é a importância desse conceito?
Devemos projetar sistemas considerando que a sobrevivência operacional de uma empresa orientada a dados depende de sua arquitetura. A importância da MDA manifesta-se nos seguintes pilares fundamentais:
- Escalabilidade Elástica: Permite aumentar ou reduzir recursos computacionais automaticamente em resposta a picos de tráfego, evitando gargalos ou capacidade ociosa.
- Time-to-Market (Agilidade): Facilita a implantação rápida de novos produtos de dados, pipelines e modelos analíticos.
- Democratização dos Dados: Viabiliza o acesso seguro e governado aos dados para diferentes perfis (Cientistas de Dados, Analistas de Negócios e Engenheiros).
- Otimização de Custos (FinOps): Ao separar armazenamento e computação, paga-se apenas pelo processamento efetivamente utilizado em nuvem (pay-as-you-go).
A Influência da IA/ML e IoT na Infraestrutura de Dados
O avanço de IA/ML (Inteligência Artificial e Machine Learning) e IoT (Internet das Coisas) tem sido um dos principais impulsionadores no desenvolvimento da infraestrutura de dados.
A capacidade de gerar e analisar grandes volumes de dados oferece uma vantagem competitiva significativa no mercado, e por isso, cada vez mais empresas buscam se transformar em “empresas de dados”, alavancando suas operações por meio de uma abordagem orientada por dados.
Como os objetivos e prioridades das empresas mudaram?
A arquitetura evoluiu significativamente devido às mudanças nos objetivos das empresas, que hoje priorizam velocidade, escalabilidade, inteligência artificial e análise em tempo real.
- Década passada (2010-2020) → Empresas focavam em relatórios estáticos, BI tradicional e ETL para armazenar e processar dados estruturados.
- Atualmente (2020-2025) → Empresas querem dados em tempo real, machine learning/IA, personalização em escala e decisões automatizadas.
Esse shift estratégico exigiu mudanças profundas na arquitetura de dados.
A abordagem tradicional, baseada em data warehouses locais e ETL tradicional, não suportava a velocidade e a variedade dos dados necessários para IA e aprendizado de máquina. Com isso, foram adotadas tecnologias baseadas na nuvem, permitindo ingestão contínua de dados via streaming, armazenamento escalável e processamento distribuído.
Isso possibilitou a utilização de arquiteturas híbridas como o conceito de lakehouse, combinando a flexibilidade de data lakes com a estruturação dos data warehouses.
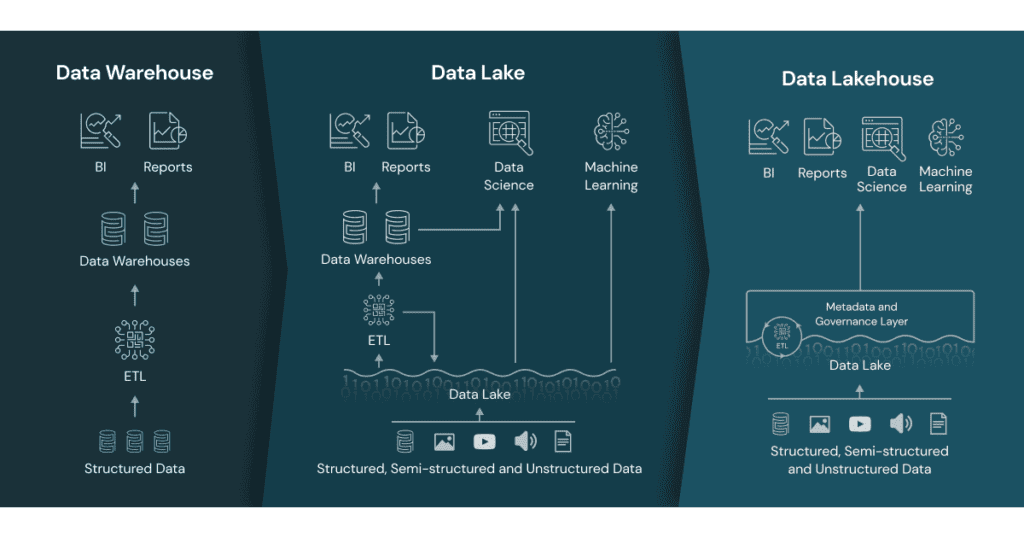
A escalabilidade também se tornou um fator crítico. Antes, as empresas investiam em servidores físicos e infraestrutura pesada, o que limitava a capacidade de crescimento. Hoje, soluções como Snowflake, BigQuery e Databricks permitem que qualquer empresa processe grandes volumes de dados sem precisar gerenciar hardware.
Além disso, a separação entre armazenamento e processamento trouxe mais eficiência ao consumo de recursos, reduzindo custos operacionais e permitindo que empresas paguem apenas pelo que utilizam.
Outro ponto fundamental é a automação e a democratização do acesso aos dados. No passado, equipes de engenharia de dados eram responsáveis por construir pipelines complexos e manter sistemas robustos, o que restringia a velocidade de inovação.
Agora, ferramentas low-code e no-code como Fivetran e dbt reduzem a necessidade de intervenção manual, permitindo que analistas e cientistas de dados foquem na geração de insights e na criação de modelos avançados de IA.
O avanço da inteligência artificial também impulsionou a adoção de novas práticas na governança de dados. Modelos de machine learning dependem da qualidade, diversidade e integridade dos dados, e isso forçou as empresas a investirem mais em soluções de observabilidade e confiabilidade, como Monte Carlo e Great Expectations.
Além disso, frameworks de engenharia de dados modernos tornaram mais fácil versionar, rastrear e auditar pipelines, garantindo que os dados usados para treinar modelos sejam confiáveis e reproduzíveis.
A mudança na arquitetura reflete a necessidade das empresas de serem mais dinâmicas, orientadas por dados e preparadas para a era da inteligência artificial. O foco deixou de ser apenas armazenar e consultar dados de forma eficiente e passou a ser sobre como transformar esses dados em vantagem competitiva, automatizando decisões e personalizando experiências em tempo real.
Exemplos de arquiteturas modernas
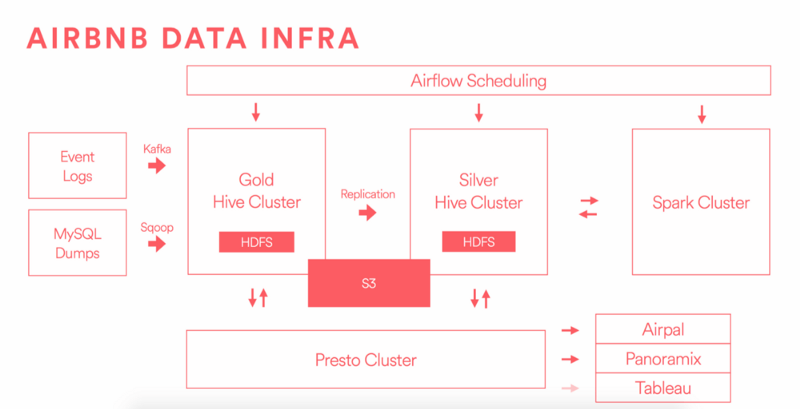
O Airbnb é um excelente exemplo de como o Modern Data Stack pode ser aplicado para lidar com grandes volumes de dados e fornecer recomendações personalizadas aos usuários. Com mais de 100 milhões de usuários e um catálogo de mais de 2 milhões de anúncios, a plataforma precisa de um sistema de dados altamente escalável e eficiente para sugerir destinos relevantes e aprimorar a experiência do usuário.
Airbnb: Infraestrutura de Dados
O time de engenharia de dados do Airbnb compartilha insights técnicos no blog AirbnbEng, onde discutem suas estratégias para gerenciar dados em larga escala.
Um dos destaques é sua arquitetura de dados moderna, que permite integrar diversas fontes de informação, realizar análises avançadas e alimentar modelos de machine learning para personalização de recomendações.
Airbnb: Investimento em Equipe de Dados
Durante um evento chamado “Building a World-Class Analytics Team“, Elena Grewal, Gerente de Ciência de Dados do Airbnb, revelou que a empresa já contava com mais de 30 engenheiros de dados.
Esse número representa um investimento significativo, estimado em mais de 5 milhões de dólares anuais apenas em salários, refletindo a importância estratégica que a empresa dá à sua infraestrutura de dados.
O caso do Airbnb ilustra como empresas inovadoras estão apostando no Modern Data Stack para escalar suas operações, melhorar a experiência do usuário e impulsionar o crescimento do negócio por meio de decisões baseadas em dados.
Principais Métodos de Implementação
Entenda as abordagens arquiteturais para implementar esses conceitos. Abaixo, detalham-se os padrões mais adotados no mercado.
Arquitetura Medalhão (Medallion Architecture)
Este é um padrão lógico de design de dados amplamente adotado em ambientes Data Lakehouse. O objetivo é melhorar a qualidade e a estrutura dos dados à medida que eles fluem pelas camadas.
| Camada | Propósito Principal | Qualidade e Estrutura | Formatos Típicos |
| Bronze (Raw) | Armazenamento do dado cru exatamente como extraído da fonte. Mantém o histórico completo. | Nula/Baixa. Estrutura original. | JSON, CSV, Parquet |
| Silver (Cleaned) | Filtragem, limpeza, padronização de tipos e deduplicação de registros. | Média. Esquema validado. | Delta, Iceberg, Hudi |
| Gold (Curated) | Agregações e modelagem orientada a regras de negócios, pronta para consumo (BI/ML). | Alta. Esquema em estrela ou tabelas analíticas. | Delta, Iceberg, Hudi |
Exemplo prático de implementação (PySpark): Transformação Bronze para Silver
Python:
# Importação de funções essenciais do PySpark
from pyspark.sql.functions import col, to_timestamp
# 1. Leitura: Extraia os dados brutos da camada Bronze
df_bronze = spark.read.format("delta").load("s3://data-lake/bronze/vendas_brutas")
# 2. Transformação: Aplique deduplicação, formatação de data e filtragem de anomalias
df_silver = df_bronze.dropDuplicates(["id_transacao"]) \
.withColumn("data_transacao", to_timestamp(col("timestamp_str"))) \
.filter(col("valor_compra") > 0) \
.dropna(subset=["id_cliente"])
# 3. Escrita: Salve os dados limpos na camada Silver no modo append
df_silver.write.format("delta").mode("append").save("s3://data-lake/silver/vendas_limpas")
Arquitetura Lambda vs. Arquitetura Kappa
Avalie a diferença de processamento para dados em lote e em fluxo contínuo.
| Critério | Arquitetura Lambda | Arquitetura Kappa |
| Caminhos de Dados | Possui duas camadas físicas separadas: Batch (histórico) e Speed (tempo real). | Possui apenas uma camada: todo dado é tratado como Stream (fluxo contínuo). |
| Complexidade de Manutenção | Alta. Exige manter duas bases de código (ex: um script para Spark Batch e outro para Spark Streaming). | Menor lógica duplicada, mas exige infraestrutura de streaming robusta e retenção longa. |
| Casos de Uso Ideais | Processamento histórico pesado acoplado com necessidades de baixa latência em dashboards temporários. | Monitoramento em tempo real absoluto, detecção de fraude, IoT. |
Principais Tecnologias Utilizadas
Para materializar essa arquitetura, aplique componentes especializados. Observe as divisões por camada estrutural:
- Ingestão e Mensageria: Apache Kafka, Amazon Kinesis, Google Pub/Sub. (Servem como o “sistema nervoso central” desacoplando produtores e consumidores de dados).
- Armazenamento (Data Lake): Amazon S3, Google Cloud Storage (GCS), Azure Data Lake Storage (ADLS).
- Formatos de Tabelas Abertas (Open Table Formats): Delta Lake, Apache Iceberg, Apache Hudi. (Adicionam a camada ACID sobre os arquivos do Data Lake).
- Processamento e Computação Distribuída: Apache Spark, Apache Flink, Databricks, Snowflake, Google BigQuery.
- Orquestração de Pipelines: Apache Airflow, Dagster, Prefect. (Garantem a ordem, execução e agendamento das tarefas).
- Catálogo de Dados e Governança: DataHub, Amundsen, AWS Glue Data Catalog, Collibra.
O Crescimento do Mercado de Software de Gerenciamento de Dados
O mercado global de software de gerenciamento de dados superou a marca de $70 bilhões em 2021, e as projeções apontam para um crescimento para $150 bilhões até 2027.
Esse aumento no interesse pela stack moderna nos últimos anos reflete a crescente adoção dessas tecnologias.
A transição das empresas para a tomada de decisões baseadas em dados gerou uma demanda crescente por processamento de dados em tempo real e ferramentas de BI/analytics.
Principais diferenças entre a stack moderna e a estrutura tradicional
A principal diferença é que a Modern Data Stack traz maior agilidade, escalabilidade e menor custo, permitindo que até pequenas empresas tenham acesso a tecnologias avançadas sem a complexidade das infraestruturas tradicionais.
| Aspecto | Stack de Dados Tradicional | Modern Data Stack (MDS) |
|---|---|---|
| Infraestrutura | On-premises (servidores físicos, data centers próprios). | Baseada na nuvem (AWS, GCP, Azure, Snowflake). |
| Escalabilidade | Limitada, exige compra de hardware adicional para crescer. | Elástica e sob demanda, cresce conforme a necessidade. |
| Armazenamento | Data Warehouses tradicionais (Ex: Oracle, Teradata). | Data Warehouses modernos (Snowflake, BigQuery, Redshift) e Data Lakes (Databricks, Delta Lake). |
| Processamento de Dados | ETL (Extract, Transform, Load) com processos pesados antes da carga. | ELT (Extract, Load, Transform), permitindo transformação pós-ingestão na nuvem. |
| Tempo de Processamento | Lento e batch (execução em horários programados). | Rápido e muitas vezes em tempo real (streaming com Kafka, Kinesis). |
| Orquestração | Ferramentas complexas e customizadas (ETL scripts). | Soluções modulares e low-code/no-code (Apache Airflow, Dagster, Prefect). |
| Integração de Dados | Demorada e cara, exige pipelines manuais e manutenção constante. | Ferramentas automatizadas (Fivetran, Airbyte, Stitch) reduzem o esforço. |
| Qualidade e Governança | Monitoramento manual, pouca observabilidade. | Ferramentas automatizadas (Monte Carlo, Great Expectations, Datafold). |
| Análise e BI | Relatórios demorados, ferramentas tradicionais (Excel, SAP BO). | Dashboards ágeis e interativos (Looker, Tableau, Metabase, Power BI). |
| Custo | Alto custo inicial e manutenção contínua de servidores. | Modelo pay-as-you-go, mais acessível para empresas de todos os portes. |
| Time Responsável | Equipes grandes e especializadas em infraestrutura e ETL. | Equipes menores, focadas em análise e engenharia de dados. |
Os data stacks tradicionais geralmente são soluções on-premises, baseadas em uma infraestrutura de hardware e software gerenciada internamente pela própria organização.
Construídos sobre arquiteturas monolíticas, esses sistemas exigem investimentos significativos tanto em infraestrutura de TI quanto em pessoal especializado. Além disso, sua integração com ambientes cloud-based costuma ser limitada, tornando-os menos flexíveis e escaláveis quando comparados às soluções modernas.
Com o crescimento exponencial do volume e da complexidade dos dados, as empresas buscam soluções mais rápidas, eficientes e econômicas para gerenciar e analisar informações.
O Marco na Evolução do Modern Data Stack
O grande avanço na stack moderna ocorreu por volta de 2012 com a introdução dos data warehouses baseados em nuvem.
Plataformas como Redshift, BigQuery e Synapse são os principais data warehouses nativos da nuvem, oferecidos pelos três principais provedores de serviços em nuvem: Amazon AWS, Google Cloud Platform (GCP) e Microsoft Azure, respectivamente.
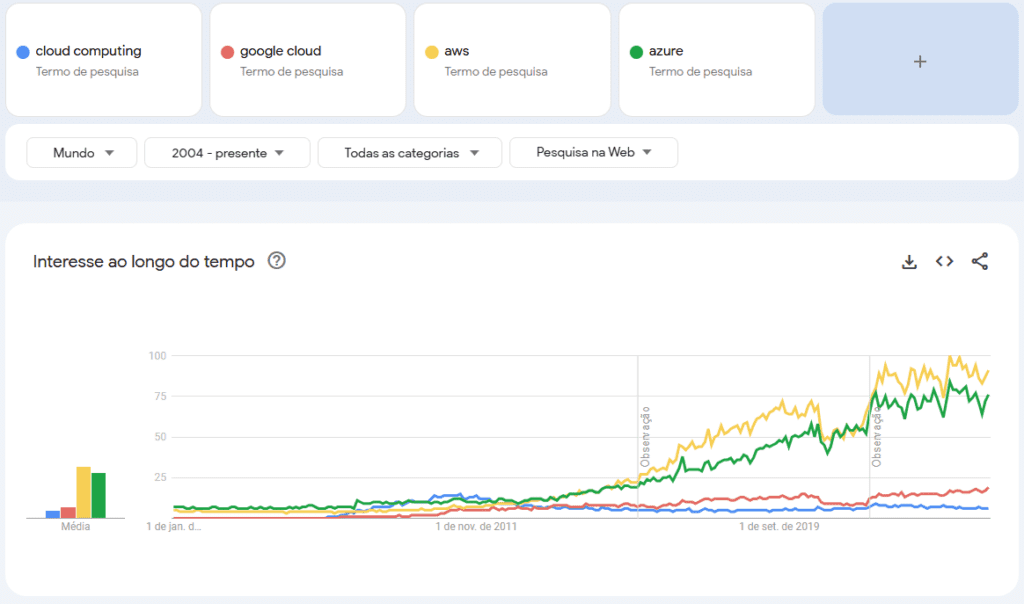
Além desses, o Snowflake também se destaca como uma solução popular de data warehouse, com a flexibilidade de ser hospedada em qualquer uma das três grandes nuvens.
Esses data warehouses trouxeram facilidade no armazenamento e utilização de dados, e sua cobrança baseada no consumo proporcionou uma flexibilidade significativa para adoção e escalabilidade.
O Crescimento do Mercado de Software de Gerenciamento de Dados
O mercado global de software de gerenciamento de dados superou a marca de $70 bilhões em 2021, e as projeções apontam para um crescimento para $150 bilhões até 2027.
Esse aumento no interesse pela stack moderna nos últimos anos reflete a crescente adoção dessas tecnologias.
A transição das empresas para a tomada de decisões baseadas em dados gerou uma demanda crescente por processamento de dados em tempo real e ferramentas de BI/analytics.
Principais diferenças entre a stack moderna e a estrutura tradicional
A principal diferença é que a Modern Data Stack traz maior agilidade, escalabilidade e menor custo, permitindo que até pequenas empresas tenham acesso a tecnologias avançadas sem a complexidade das infraestruturas tradicionais.
| Aspecto | Stack de Dados Tradicional | Modern Data Stack (MDS) |
|---|---|---|
| Infraestrutura | On-premises (servidores físicos, data centers próprios). | Baseada na nuvem (AWS, GCP, Azure, Snowflake). |
| Escalabilidade | Limitada, exige compra de hardware adicional para crescer. | Elástica e sob demanda, cresce conforme a necessidade. |
| Armazenamento | Data Warehouses tradicionais (Ex: Oracle, Teradata). | Data Warehouses modernos (Snowflake, BigQuery, Redshift) e Data Lakes (Databricks, Delta Lake). |
| Processamento de Dados | ETL (Extract, Transform, Load) com processos pesados antes da carga. | ELT (Extract, Load, Transform), permitindo transformação pós-ingestão na nuvem. |
| Tempo de Processamento | Lento e batch (execução em horários programados). | Rápido e muitas vezes em tempo real (streaming com Kafka, Kinesis). |
| Orquestração | Ferramentas complexas e customizadas (ETL scripts). | Soluções modulares e low-code/no-code (Apache Airflow, Dagster, Prefect). |
| Integração de Dados | Demorada e cara, exige pipelines manuais e manutenção constante. | Ferramentas automatizadas (Fivetran, Airbyte, Stitch) reduzem o esforço. |
| Qualidade e Governança | Monitoramento manual, pouca observabilidade. | Ferramentas automatizadas (Monte Carlo, Great Expectations, Datafold). |
| Análise e BI | Relatórios demorados, ferramentas tradicionais (Excel, SAP BO). | Dashboards ágeis e interativos (Looker, Tableau, Metabase, Power BI). |
| Custo | Alto custo inicial e manutenção contínua de servidores. | Modelo pay-as-you-go, mais acessível para empresas de todos os portes. |
| Time Responsável | Equipes grandes e especializadas em infraestrutura e ETL. | Equipes menores, focadas em análise e engenharia de dados. |
Os data stacks tradicionais geralmente são soluções on-premises, baseadas em uma infraestrutura de hardware e software gerenciada internamente pela própria organização.
Construídos sobre arquiteturas monolíticas, esses sistemas exigem investimentos significativos tanto em infraestrutura de TI quanto em pessoal especializado. Além disso, sua integração com ambientes cloud-based costuma ser limitada, tornando-os menos flexíveis e escaláveis quando comparados às soluções modernas.
Pontos positivos e negativos que essa evolução trouxe consigo
O Modern Data Stack trouxe eficiência, escalabilidade e acessibilidade ao mundo dos dados, mas ainda existem desafios críticos a serem resolvidos.
O futuro dependerá da evolução de governança de dados, streaming analytics, integração com ferramentas operacionais e interfaces mais acessíveis para usuários não técnicos em alguns cenários.
| Pontos positivos | Pontos Negativos |
|---|---|
| Produtos Horizontais Antigamente, era necessário adquirir várias ferramentas específicas para analisar diferentes conjuntos de dados. Com o MDS, os dados são centralizados em um data warehouse, permitindo a análise unificada em uma única stack de ferramentas comuns. Velocidade O MDS permite uma conexão rápida com novas fontes de dados e facilita a exploração analítica. A performance dos bancos de dados MPP (Massively Parallel Processing) proporciona alta velocidade de execução de queries, acelerando o processo de tomada de decisão. Escalabilidade Ilimitada Com a infraestrutura em nuvem, é possível escalar o processamento e armazenamento de dados sem limites técnicos significativos. O principal fator limitante passou a ser o custo, e não a capacidade da tecnologia. Baixo Overhead Operacional Em 2012, era necessário um time robusto de engenheiros para gerenciar a infraestrutura de dados. Hoje, o MDS reduz essa necessidade, tornando possível operar pipelines de dados sofisticados sem grandes investimentos em infraestrutura e engenharia. Integração Padronizada via SQL No passado, não havia um padrão claro para integração entre diferentes produtos de dados. Atualmente, SQL é a linguagem comum em todos os componentes do MDS, facilitando a integração e democratizando o acesso aos dados para um público mais amplo. | Governança Imatura: A facilidade de coletar e transformar dados na stack moderna traz riscos de desorganização. Ainda faltam ferramentas e boas práticas para garantir confiança, segurança e contexto nos dados. Arquitetura Baseada em Lotes (Batch Processing) O MDS ainda opera majoritariamente em processamento em lote, utilizando agendamentos e polling para coletar dados. A transição para streaming poderia desbloquear ainda mais valor, permitindo uma análise quase em tempo real. Falta de Integração com Ferramentas Operacionais Atualmente, os dados fluem apenas em uma direção, das fontes para o data warehouse e para dashboards. Para maximizar o impacto, seria essencial integrar os insights diretamente com ferramentas operacionais como CRMs, plataformas de e-commerce e sistemas de mensagens. Acesso Limitado para Consumidores de Dados Apesar da acessibilidade via SQL, muitos consumidores de dados ainda dependem de analistas para realizar consultas. No passado, usuários finais tinham maior autonomia utilizando ferramentas familiares como Excel, algo que ainda não foi completamente resolvido na stack moderna. Perda de Experiências Analíticas Verticais A consolidação dos dados em infraestruturas centralizadas eliminou algumas ferramentas especializadas por domínio. Experiências analíticas otimizadas para áreas como marketing, vendas e mobile analytics são fundamentais para garantir insights mais precisos e contextualizados. |
Melhores Práticas de Mercado
Para construir infraestruturas resilientes e de nível de produção (Enterprise-grade), adote rigorosamente as seguintes práticas:
- Implemente princípios de DataOps: Adote o versionamento de código, controle de infraestrutura com repositórios e CI/CD (Integração e Entrega Contínuas) para pipelines de dados, tratando dados com a mesma disciplina da engenharia de software tradicional.
- Utilize Infraestrutura como Código (IaC): Provisão de recursos na nuvem (buckets de armazenamento, clusters de processamento, políticas de IAM) exclusivamente através de código usando Terraform ou ferramentas equivalentes.
- Projete para a Idempotência: Assegure que os pipelines de processamento (jobs de Spark, DAGs do Airflow) possam ser re-executados múltiplas vezes em caso de falha sem gerar duplicação de dados.
- Aplique testes de Qualidade de Dados precocemente (Shift-Left): Realize verificações rigorosas de esquema e sanidade de dados nos estágios iniciais de ingestão (na transição de Bronze para Silver), bloqueando ou isolando registros inválidos (padrão Dead Letter Queue ou camada de quarentena).
Principais Desafios e Considerações Gerais
Implementar uma Modern Data Architecture exige gerenciar complexidades inerentes a sistemas distribuídos. Considere com cautela os seguintes pontos:
- Curva de Aprendizado e Complexidade Tecnológica: Sistemas distribuídos possuem alto acoplamento de rede e exigem profundo conhecimento de sistemas Linux, redes e conteinerização (Docker/Kubernetes).
- Governança de Dados em Ambientes Descentralizados: Garantir a conformidade (ex: LGPD/GDPR), mascaramento de dados sensíveis (PII) e o rastreamento do ciclo de vida do dado (Data Lineage) torna-se exponencialmente mais difícil quando há múltiplos domínios de dados.
- Qualidade de Dados (Data Quality): Com a velocidade da ingestão de sistemas fonte diversos, o princípio Garbage In, Garbage Out é amplificado.
- Controle Rigoroso de Custos (FinOps): Processamento elástico pode gerar faturas de nuvem estratosféricas se o código estiver mal otimizado (ex: escaneamento de partições inteiras por falta de filtros adequados nas queries).
Referências:
- https://www.getdbt.com/blog/future-of-the-modern-data-stack
- https://keen.io/blog/architecture-of-giants-data-stacks-at-facebook-netflix-airbnb-and-pinterest/
- https://www.altexsoft.com/blog/modern-data-stack/
- https://kae-capital.com/blogs/the-modern-data-stack/
- https://medium.com/@kamini_74876/key-trends-in-modern-data-stack-4dd6f213f7e6
