Analise o cenário atual da infraestrutura de dados. Historicamente, as empresas mantinham duas pilhas tecnológicas separadas:
- o Data Warehouse (DW) para Business Intelligence (BI) e dados estruturados
- o Data Lake para Machine Learning (ML), Big Data e dados não estruturados.
Essa separação criava silos, redundância de dados e alta complexidade de manutenção.
Imagine um e-commerce hipotético, o “LojaTech”. Para calcular o faturamento mensal (BI), a LojaTech usa um DW tradicional (como um banco SQL robusto). Porém, para recomendar produtos com base em cliques em tempo real (ML), ela joga logs brutos em um Data Lake (armazenamento de arquivos barato).
O problema surge quando o time de ML precisa cruzar os dados de cliques com o histórico de compras do DW. Eles precisam criar pipelines complexos para mover dados de um lado para o outro. O resultado? Dados inconsistentes e atraso na informação.
O Data Lakehouse surge para eliminar essa dicotomia, permitindo que a LojaTech faça BI e ML sobre a mesma fonte de dados, com baixo custo e alta governança.
O Que é o Data Lakehouse? (Definição sob a ótica de Engenharia de Dados)
Defina o Data Lakehouse como uma arquitetura de gerenciamento de dados que combina a flexibilidade, eficiência de custo e escala de um Data Lake com o gerenciamento de dados, transações ACID e suporte a esquemas de um Data Warehouse.
Na prática de engenharia, entenda que o Lakehouse não é apenas “instalar uma ferramenta”, mas sim implementar uma camada de metadados e controle transacional sobre arquivos brutos (normalmente Parquet ou Avro) armazenados em um Object Storage (como S3, ADLS ou GCS).
Essa arquitetura desacopla fundamentalmente o processamento (Compute) do armazenamento (Storage), permitindo escalar cada um independentemente, mas garantindo que o motor de processamento “enxergue” os arquivos como tabelas estruturadas e confiáveis.
Qual é a importância desse conceito?
A importância reside na unificação das cargas de trabalho. Ao aplicar um Lakehouse, elimina-se a necessidade de manter cópias duplicadas de dados em sistemas distintos (um para analistas de SQL e outro para cientistas de dados).
Isso resulta em:
- Confiabilidade de Dados: Introdução de transações ACID em Data Lakes, evitando leituras de dados parciais ou corrompidos durante falhas de gravação.
- Governança Simplificada: Um único ponto de controle para segurança e auditoria.
- Time Travel: Capacidade de consultar versões anteriores dos dados para auditoria ou rollback (reversão) de erros.
Observe a comparação estrutural abaixo:
| Característica | Data Warehouse | Data Lake | Data Lakehouse |
| Tipo de Dados | Estruturados | Estruturados, Semi e Não-Estruturados | Todos (Estruturados a Não-Estruturados) |
| Custo de Armazenamento | Alto (Discos rápidos/Proprietário) | Baixo (Object Storage) | Baixo (Object Storage) |
| Transações | ACID Completo | Não suporta (Atomicidade por arquivo) | ACID Completo |
| Qualidade dos Dados | Alta (Curada) | Baixa (Pântano de dados) | Alta (Curada e Validada) |
| Público Alvo | Analistas de BI | Cientistas de Dados | Analistas de BI e Cientistas de Dados |
Exemplos Práticos Reais em empresas
O WeChat, com mais de 1,3 bilhão de usuários, precisou evoluir sua arquitetura de dados para lidar com volumes massivos, consultas complexas e baixa latência. A arquitetura legada baseada em Hadoop e múltiplos data warehouses gerava alto custo operacional, problemas de governança e dificuldade de padronização.
Para resolver isso, a empresa adotou uma arquitetura unificada de data lakehouse, usando StarRocks para consultas de baixa latência, Apache Spark para processamento em batch e Apache Iceberg sobre arquivos Parquet no storage em nuvem. Essa abordagem suporta ingestão em tempo real e quase em tempo real.
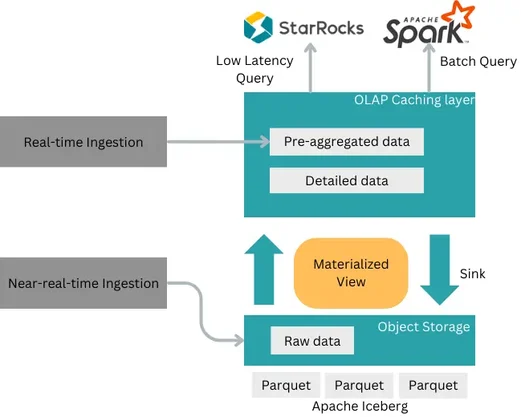
Como resultado, o WeChat simplificou sua arquitetura, melhorou a atualização dos dados e reduziu significativamente a latência das consultas, alcançando níveis sub-segundo. Além disso, obteve ganhos operacionais relevantes, como redução de custos de armazenamento em mais de 65% e diminuição do esforço e do tempo de desenvolvimento para engenheiros de dados.
Como o design Lakehouse do WeChat lida de forma eficiente com trilhões de registros
Principais Métodos de Implementação
Implemente o Data Lakehouse organizando os dados em zonas lógicas de refinamento. A arquitetura mais comum e recomendada é a Arquitetura Medalhão (Medallion Architecture). Projete seu pipeline seguindo estas camadas:
- Camada Bronze (Raw):
- Receba os dados no formato original (JSON, CSV, Parquet) vindo das fontes.
- Não aplique transformações de negócio, apenas adicione metadados de ingestão (data de carga, origem).
- Objetivo: Ter um histórico imutável e permitir o reprocessamento em caso de erro.
- Camada Prata (Silver/Enriched):
- Limpe, deduplique e padronize os dados da Bronze.
- Aplique tipos de dados corretos (cast strings para dates/integers).
- Enforce o Schema Enforcement aqui.
- Objetivo: Dados limpos prontos para exploração de Data Science.
- Camada Ouro (Gold/Curated):
- Realize agregações, joins complexos e aplique regras de negócio finais (ex: Tabela Fato e Dimensão).
- Modele em Star Schema (Kimball) se necessário.
- Objetivo: Dados prontos para consumo de dashboards de BI e relatórios executivos.
Principais tecnologias utilizadas
Para construir um Lakehouse, selecione tecnologias que suportem formatos de tabela aberta (Open Table Formats). Não confunda o armazenamento físico com o formato lógico.
1. Formatos de Tabela (A Camada de Metadados)
Estes são os componentes que transformam o Data Lake em Lakehouse, permitindo ACID e controle de versão:
- Delta Lake: (Líder de mercado, mantido pela Linux Foundation). Altamente otimizado para Spark, suporta schema enforcement e evolution nativamente.
- Apache Iceberg: (Originado na Netflix). Focado em tabelas gigantescas, excelente suporte a evolução de esquema oculta e particionamento dinâmico.
- Apache Hudi: (Originado na Uber). Focado em streaming e atualizações/deletes pesados (Upserts).
2. Motores de Processamento (Compute)
- Apache Spark: O motor padrão para processamento massivo em Lakehouses.
- Trino (antigo PrestoSQL): Excelente para consultas SQL federadas e interativas sobre o Lakehouse.
- Databricks SQL / Starburst: Versões empresariais gerenciadas dos motores acima.
3. Armazenamento (Storage)
- AWS S3, Azure Data Lake Gen2, Google Cloud Storage.
Exemplo de Código (PySpark com Delta Lake):
Observe como a sintaxe é similar à manipulação de tabelas SQL, abstraindo a complexidade dos arquivos:
# Lendo dados brutos
df_bronze = spark.read.format("json").load("/mnt/bronze/vendas.json")
# Gravando na camada Silver em formato Delta (Garante ACID)
df_bronze.write \
.format("delta") \
.mode("overwrite") \
.save("/mnt/silver/vendas_clean")
# Realizando uma atualização (UPDATE) - Algo impossível em Data Lakes puros
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/mnt/silver/vendas_clean")
# Atualiza desconto para 10% onde o produto for 'Camiseta'
deltaTable.update(
condition = "produto = 'Camiseta'",
set = { "desconto": "0.10" }
)
Principais Desafios e Considerações Gerais
Esteja ciente dos obstáculos ao projetar esta arquitetura:
- Problema de Arquivos Pequenos (Small Files Problem): Ingestão em streaming pode gerar milhares de arquivos minúsculos (kb), degradando a performance de leitura. É obrigatório implementar rotinas de Compaction (unificar arquivos pequenos em maiores).
- Gerenciamento de Metadados: Conforme o Lakehouse cresce, o catálogo de metadados (ex: Hive Metastore ou Unity Catalog) pode se tornar um gargalo se não for bem dimensionado.
- Latência: Embora rápido, um Lakehouse puro pode ter latência maior que um Data Warehouse proprietário em memória para consultas muito específicas de sub-segundos.
Melhores Práticas de Mercado
Adote estas práticas para garantir performance e manutenibilidade:
- Otimize o Layout dos Dados (Z-Ordering/Optimize): Utilize comandos como
OPTIMIZEeZ-ORDER(no Delta Lake) para co-localizar dados relacionados nos mesmos arquivos, acelerando drasticamente as consultas que usam filtros (Data Skipping). - Particionamento Inteligente: Não particione colunas com alta cardinalidade (ex: ID do cliente), pois isso gera milhões de arquivos e diretórios. Prefira particionar por Data (Ano/Mês) ou Região.
- Rotinas de Limpeza (Vacuum): O Lakehouse guarda histórico de tudo (Time Travel). Configure rotinas de
VACUUMpara deletar arquivos físicos de versões muito antigas e economizar custos de armazenamento. - Use Catalogs Unificados: Utilize ferramentas como Unity Catalog ou AWS Glue Data Catalog para centralizar as permissões de acesso. Nunca gerencie acesso diretamente no nível do arquivo (ACLs de S3), gerencie no nível da tabela.
