Aqui, a pergunta não é “se” algo vai falhar, mas “quando”. E quando falhar, o seu sistema precisa ser inteligente o suficiente para se curar sem corromper os dados.
Imagine que você está em um elevador e aperta o botão do 5º andar. Se você apertar esse mesmo botão dez vezes seguidas, o elevador ainda te levará para o 5º andar, certo? Ele não vai somar os cliques e te levar para o 50º andar.
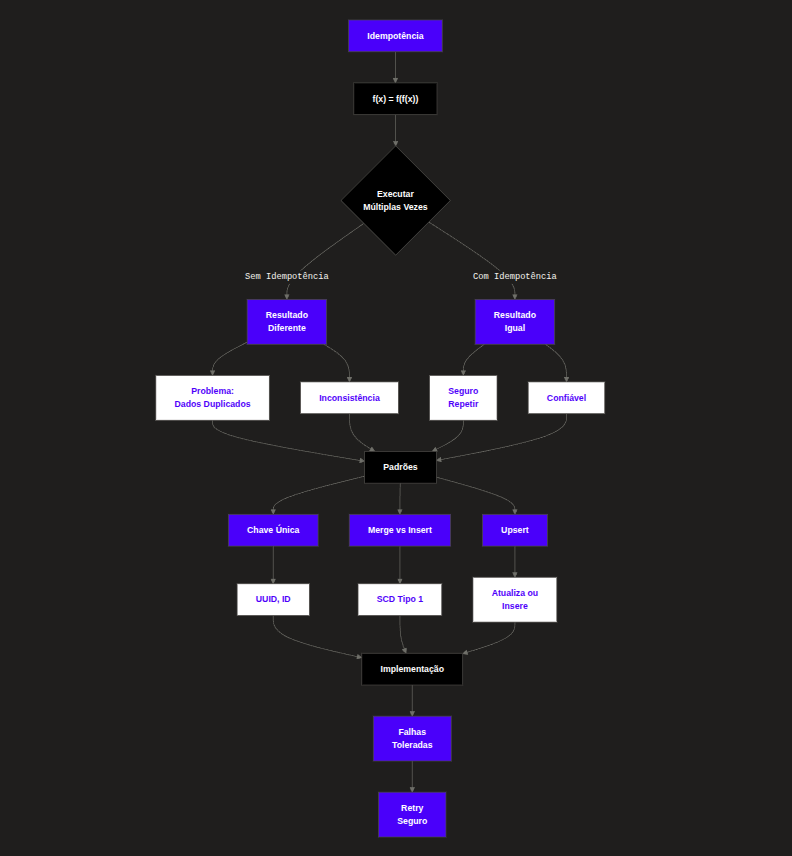
Isso é idempotência. No mundo da Engenharia de Dados, esse conceito é um dos pilares para construir sistemas confiáveis e à prova de falhas.
O que é Idempotência? (Definição e Óticas)
Em resumo: Idempotência é a propriedade de poder realizar a mesma ação várias vezes e obter o mesmo resultado que se tivesse realizado apenas uma vez.
A. Ótica da Engenharia de Software (APIs)
Imagine um botão de “Chamar Elevador”. Você pode apertá-lo uma vez ou vinte vezes seguidas impacientemente. O sistema entende: “O elevador foi chamado”. Ele não manda 20 elevadores para o seu andar.
Em APIs REST:
- POST geralmente não é idempotente (cria um novo recurso a cada chamada).
- PUT e DELETE devem ser idempotentes (se eu deletar o usuário ID 10 duas vezes, na segunda vez o resultado final é o mesmo: o usuário não existe).
B. Ótica da Engenharia de Dados
Aqui é onde o jogo muda. Idempotência em pipelines de dados significa que você pode reprocessar um arquivo, uma mensagem ou um lote de dados inteiro sem gerar duplicidade no destino final.
Se o seu script Python falhar na metade e você rodá-lo de novo:
- Pipeline Não-Idempotente: Você terá metade dos dados duplicados no banco.
- Pipeline Idempotente: O sistema detecta o que já foi processado, atualiza o que mudou ou simplesmente sobrescreve o destino de forma segura, garantindo integridade.
Qual a sua importância?
Por que devemos exigir idempotência idealmente em todos os projetos de dados?
- Tolerância a Falhas (Fault Tolerance): Redes caem. Servidores reiniciam. Em um sistema distribuído, a estratégia padrão de recuperação é o Retry (tentar novamente). Se o seu processo não for idempotente, você não pode usar retries automáticos sem corromper o banco.
- Consistência de Dados: Garante a semântica de Exactly-Once (Exatamente uma vez). O analista de BI ou o Cientista de Dados na ponta final confiará que o número de vendas é real, e não inflado por reprocessamentos.
- Redução de Custos Operacionais: Imagine o custo de horas de engenharia para escrever scripts de “limpeza” (Deduplication) toda vez que um job falhar. Com a idempotência, a recuperação é apenas “rodar o job de novo”.
Exemplo Prático Real (Engenharia de Dados)
Cenário: O E-commerce “TechVendas”
Você é responsável por ingerir as vendas do dia anterior no Data Warehouse para o relatório financeiro.
- Input: Arquivo
vendas_2023-10-27.csvcom 1 milhão de linhas. - O Evento: O job começa a rodar às 03:00 AM. Ele insere 500.000 linhas no banco de dados. Às 03:15 AM, a conexão cai e o script quebra.
| Sem Idempotência (O Caos) | Com Idempotência (O Ideal) |
|---|---|
| O orquestrador (airflow, por exemplo) tenta rodar o job novamente. O script lê o arquivo do zero. Ele insere as 500.000 linhas (que já foram inseridas antes da falha). Ele continua e insere as outras 500.000 linhas restantes. Resultado: O banco tem 1.5 milhões de registros. A receita do dia aparece 50% maior. O CEO toma decisões erradas baseadas em lucro inexistente. | O orquestrador roda o job novamente. O script usa uma estratégia de Upsert ou Overwrite Partition. Ao encontrar as 500.000 linhas que já existem (baseado no ID da venda), ele apenas confirma que estão iguais ou as atualiza. Ele insere as novas 500.000 linhas. Resultado: O banco tem exatamente 1 milhão de registros. Dados consistentes. Você continua dormindo tranquilamente. |
Principais Métodos de Implementação
Como você escreve isso no código? Aqui estão as três abordagens clássicas:
1. DELETE-WRITE (Sobrescrita de Partição)
É a abordagem mais simples e robusta para processamento em lote (Batch).
Lógica: Antes de escrever, apague tudo que existe para aquele período/partição específica.
Exemplo SQL:
-- Passo 1: Limpa a "mesa" para o dia específico
DELETE FROM tabela_vendas WHERE data_venda = '2023-10-27';
-- Passo 2: Escreve os dados novos limpos
INSERT INTO tabela_vendas SELECT * FROM arquivo_staging;2. UPSERT (Merge)
Ideal quando você não pode apagar dados (ex: atualizações de status de pedidos). O banco verifica linha a linha.
Lógica: Se a chave (ID) existe -> Atualiza (Update). Se não existe -> Insere (Insert).
Exemplo (Conceitual Python/Pandas):
# Não faça append cego!
# Lógica de Merge pseudo-código
for row in dataframe:
if database.exists(row.id):
database.update(row)
else:
database.insert(row)3. Tabela de Controle (Watermarking)
Você mantém uma tabela auxiliar que registra quais arquivos já foram processados.
- Lógica: O script verifica: “O arquivo X já foi processado com sucesso?”. Se sim, pula. Se não, processa e marca como concluído no final.
Desafios e Considerações
Nem tudo são flores. Implementar idempotência tem um custo:
Performance (Overhead):
- Fazer um
INSERTdireto (append) é extremamente rápido. - Fazer um
UPSERTexige que o banco leia o índice para ver se o ID existe antes de escrever. Isso é mais lento e consome mais CPU.
Complexidade de Design:
Você precisa definir muito bem suas Chaves Primárias (Primary Keys). Se seus dados não tiverem um ID único confiável, a idempotência fica quase impossível.
Janelas de Tempo (Late Arriving Data):
No método Delete-Write, se chegar um dado atrasado de 3 dias atrás, você precisa reprocessar a partição daquele dia antigo, não a de hoje.
Melhores Práticas (Diretrizes de Ouro)
- Defina uma Chave Única (Natural Key): Nunca confie apenas em IDs gerados automaticamente pelo banco (auto-increment). Tente usar algo do negócio (ex:
NumeroPedidoou uma combinaçãoData + ID_Cliente + SKU).
- Particionamento é Vida: Sempre que possível, trabalhe com partições (por data é o mais comum). É muito mais barato apagar e reescrever uma partição de um dia (
DELETE WHERE date = X) do que fazer Upsert na tabela inteira.
- Imutabilidade na Origem: Nunca modifique o arquivo bruto (Raw Data). Se precisar reprocessar, a fonte original deve estar intocada.
- Use Transações (Atomocidade): Em bancos relacionais, envolva suas operações de limpeza e escrita em uma transação. Se a escrita falhar, o
DELETEinicial é desfeito (rollback), evitando que você perca dados se o script quebrar no meio.
- Teste a Falha: Não teste apenas o “Caminho Feliz”. Force o erro no meio do script e rode de novo. Se duplicar dados no ambiente de desenvolvimento, seu design falhou.
